转载:Using ES6 with gulp
Nov 2nd, 2015
- As of node 4, we’re now able to use ES2015 without the need for Babel. However modules are not currently supported so you’ll need to use `require()` still. Checkout the node docs for more info on what’s supported. If you’d like module support and to utilise Babel, read on.
- Post updated to use Babel 6.
With gulp 3.9, we are now able to use ES6 (or ES2015 as it’s now named) in our gulpfile—thanks to the awesome Babel transpiler.
Firstly make sure you have at least version 3.9 of both the CLI and local version of gulp. To check which version you have, open up terminal and type:
This should return:
CLI version 3.9.0
Local version 3.9.0
If you get any versions lower than 3.9, update gulp in your package.json file, and run the following to update both versions:
npm install gulp && npm install gulp -g
Creating an ES6 gulpfile
To leverage ES6 you will need to install Babel (make sure you have Babel 6) as a dependency to your project, along with the es2015 plugin preset:
npm install babel-core babel-preset-es2015 --save-dev
Once this has finished, we need to create a .babelrc config file to enable the es2015 preset:
And add the following to the file:
{
"presets": ["es2015"]
}
We then need to instruct gulp to use Babel. To do this, we need to rename the gulpfile.js to gulpfile.babel.js:
mv "gulpfile.js" "gulpfile.babel.js"
We can now use ES6 via Babel! An example of a typical gulp task using new ES6 features:
'use strict';
import gulp from 'gulp';
import sass from 'gulp-sass';
import autoprefixer from 'gulp-autoprefixer';
import sourcemaps from 'gulp-sourcemaps';
const dirs = {
src: 'src',
dest: 'build'
};
const sassPaths = {
src: `${dirs.src}/app.scss`,
dest: `${dirs.dest}/styles/`
};
gulp.task('styles', () => {
return gulp.src(paths.src)
.pipe(sourcemaps.init())
.pipe(sass.sync().on('error', plugins.sass.logError))
.pipe(autoprefixer())
.pipe(sourcemaps.write('.'))
.pipe(gulp.dest(paths.dest));
});
Here we have utilised ES6 import/modules, arrow functions, template strings and constants. If you’d like to check out more ES6 features, es6-features.org is a handy resource.
 第k次迭代为:
第k次迭代为:![\[ m_k(p)=f_k + \nabla f_k^T p+\frac{1}{2} p^T B_k p \qquad\qquad\qquad Equitation 1 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-d1060385dc1a33ec7865560a5fae76ef_l3.png "Rendered by QuickLaTeX.com")
 为n x n对称正定矩阵,可以在每次迭代中更新。注意到这个构造函数在p=0的时候,
为n x n对称正定矩阵,可以在每次迭代中更新。注意到这个构造函数在p=0的时候, 和
和 和原函数是相同的。对其求导,得到
和原函数是相同的。对其求导,得到![\[ p_k= - B_k^{-1} \nabla f_k \qquad\qquad\qquad Equitation 2 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-b49c9e17e378c2745ec30ca957681ed0_l3.png "Rendered by QuickLaTeX.com")
 第k+1次迭代为(其中
第k+1次迭代为(其中 可以用强Wolfe准则来计算):
可以用强Wolfe准则来计算):![\[ x_{k+1}= x_k + \alpha_k p_k \qquad\qquad\qquad Equitation 3 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-5d87d1796b214da34d89d90747aa6887_l3.png "Rendered by QuickLaTeX.com")
![\[ m_{k+1}(p)=f_{k+1} + \nabla f_{k+1}^T p+\frac{1}{2} p^T B_{k+1} p \qquad\qquad\qquad Equitation 4 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-6984d2187c63c5f0b03c9852e3410a09_l3.png "Rendered by QuickLaTeX.com")
 呢?函数
呢?函数 应该在
应该在 导数一致。对其求导,并令
导数一致。对其求导,并令 ,即
,即 )
)![\[ \nabla m_{k+1}( - \alpha_k p_k )= \nabla f_{k+1} - \alpha_k B_{k+1} p_k = \nabla f_k \qquad\qquad\qquad Equitation 5 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-31e649a173029279a7b1c43d89f60637_l3.png "Rendered by QuickLaTeX.com")
![\[ B_{k+1} \alpha_k p_k = \nabla f_{k+1} - \nabla f_k \qquad\qquad\qquad Equitation 6 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-4db45036c89babeba307a16076258377_l3.png "Rendered by QuickLaTeX.com")
 ,方程6为:
,方程6为:![\[ B_{k+1} s_k = y_k \qquad\qquad\qquad Equitation 7 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-16a47524446a020f8c68cb2b80f1ceda_l3.png "Rendered by QuickLaTeX.com")
 ,得到另一个形式:
,得到另一个形式:![\[ H_{k+1} y_k = s_k \qquad\qquad\qquad Equitation 8 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-0d6f3e544c82c49fe67d2691f3f42348_l3.png "Rendered by QuickLaTeX.com")
![\[ p_k= - H_k \nabla f_k \qquad\qquad\qquad Equitation 9 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-15faa30f2e63791ca7b1dce07db6cb2c_l3.png "Rendered by QuickLaTeX.com")
![\[ B_{k+1}= B_k + E_k , H_{k+1}= H_k + D_k \qquad\qquad\qquad Equitation 10 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-39de6f917f917e77328512c325ab2906_l3.png "Rendered by QuickLaTeX.com")
 和
和 为秩1或秩2的矩阵。
为秩1或秩2的矩阵。![\[ E_k = \alpha u_k u_k^T + \beta v_k v_k^T \qquad\qquad\qquad Equitation 11 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-702b044e2b7728bb406cc8fcba0327af_l3.png "Rendered by QuickLaTeX.com")
![\[ ( B_k + \alpha u_k u_k^T + \beta v_k v_k^T )s_k = y_k \qquad\qquad\qquad Equitation 12 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-0c12c30228690068a662e7b5635240bd_l3.png "Rendered by QuickLaTeX.com")
![\[ \alpha ( u_k^T s_k ) u_k + \beta ( v_k^T s_k ) v_k = y_k - B_k s_k \qquad\qquad\qquad Equitation 13 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-a12d88b484e83de57c8d40ca2b9cdca0_l3.png "Rendered by QuickLaTeX.com")
 和
和 不唯一,令
不唯一,令 和
和 ,即
,即 和
和 ,带入方程11得:
,带入方程11得:![\[ E_k = \alpha \gamma^2 B_k s_k s_k^T B_k + \beta \theta^2 y_k y_k^T \qquad\qquad\qquad Equitation 14 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-0441bdf028d372c9fec243fcc0e785d0_l3.png "Rendered by QuickLaTeX.com")
![\[ \alpha ( (\gamma B_k s_k)^T s_k ) (\gamma B_k s_k) + \beta ( (\theta y_k)^T s_k ) (\theta y_k) = y_k - B_k s_k \qquad\qquad\qquad Equitation 15 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-ff38b699c2974b30483427deb538fb58_l3.png "Rendered by QuickLaTeX.com")
![\[ [ \alpha \gamma^2 (s_k^T B_k s_k) + 1 ]B_k s_k + [\beta \theta^2 (y_k^T s) - 1 ]y_k = 0 \qquad\qquad\qquad Equitation 16 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-42318c26ddc4f1caa2df118d6c209bed_l3.png "Rendered by QuickLaTeX.com")
 ,
, ,
, ,
, 。
。![\[ B_{k+1} = B_k - \frac{B_k s_k s_k^T B_k}{s_k^T B_k s_k} + \frac{y_k y_k^T}{y_k^T s_k} \qquad\qquad\qquad Equitation 17 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-1cceb1e343a1978937fab065edd37652_l3.png "Rendered by QuickLaTeX.com")
![\[ B_{k+1}^{-1} = (B_k - \frac{B_k s_k s_k^T B_k}{s_k^T B_k s_k} + \frac{y_k y_k^T}{y_k^T s_k})^{-1} \qquad\qquad\qquad Equitation 18 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-9b90290cce22b76e862636f1c7e10d2d_l3.png "Rendered by QuickLaTeX.com")
![\[ (A + UCV)^{-1} = A^{-1} - \frac{A^{-1}UVA^{-1}}{C^{-1} + VA^{-1}U} \qquad\qquad\qquad Sherman Morison Woodbury Equitation \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-20a3b37384085495ed92451031d4437a_l3.png "Rendered by QuickLaTeX.com")
 是方程中的
是方程中的
![\[ B_{k+1}^{-1} = (I - \frac{s_k y_k^T}{y_k^T s_k}) B_k^{-1} (I - \frac{y_k s_k^T}{y_k^T s_k}) + \frac{s_k s_k^T}{y_k^T s_k} \qquad\qquad\qquad Equitation 19 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-96e252069fa2cd4fff3d7bd6db3861d8_l3.png "Rendered by QuickLaTeX.com")
 ,方程19可得BFGS方法的迭代方程:
,方程19可得BFGS方法的迭代方程:![\[ H_{k+1} = (I - \rho s_k y_k^T }) H_k (I - \rho y_k s_k^T}) + \rho s_k s_k^T \qquad\qquad\qquad BFGS Equitation \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-1074f808a1ae6215fa48ba562803ae93_l3.png "Rendered by QuickLaTeX.com")
 ,则BFGS方程可写成:
,则BFGS方程可写成:![\[ H_{k+1} = V_k^T H_k V_k + \rho s_k s_k^T \qquad\qquad\qquad Equitation 20 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-c514a95ac49f339f139e042444e8c69d_l3.png "Rendered by QuickLaTeX.com")

 需要用到
需要用到 组数据,数据量非常大,LBFGS算法就采取只去最近的m组数据来运算,即可以构造近似计算公式:
组数据,数据量非常大,LBFGS算法就采取只去最近的m组数据来运算,即可以构造近似计算公式:
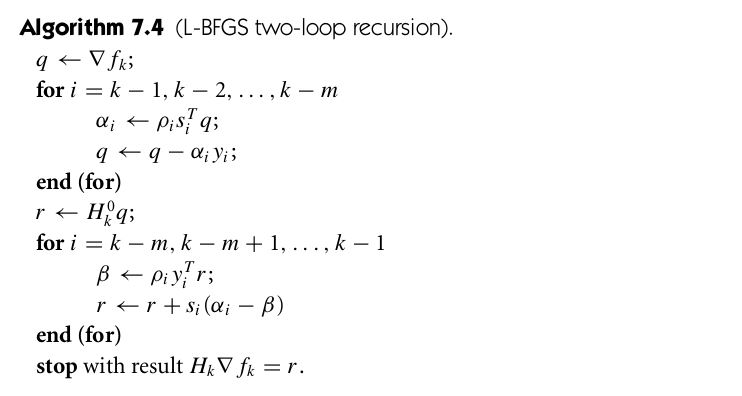
 :
:
 ,这里的m指的是从现在到历史记录m次的后一次,因为LBFGS只记录m次历史:
,这里的m指的是从现在到历史记录m次的后一次,因为LBFGS只记录m次历史: