原创文章,转载请注明: 转载自慢慢的回味
本文链接地址: ALS-WR(协同过滤推荐算法) in ML
简介
ALS-WR算法,简单地说就是:
(数据格式为:userId, itemId, rating, timestamp )
1 对每个userId随机初始化N(10)个factor值,由这些值影响userId的权重。
2 对每个itemId也随机初始化N(10)个factor值。
3 固定userId,从userFactors矩阵和rating矩阵中分解出itemFactors矩阵。即[Item Factors Matrix] = [User Factors Matrix]^-1 * [Rating Matrix].
4 固定itemId,从itemFactors矩阵和rating矩阵中分解出userFactors矩阵。即[User Factors Matrix] = [Item Factors Matrix]^-1 * [Rating Matrix].
5 重复迭代第3,第4步,最后可以收敛到稳定的userFactors和itemFactors。
6 对itemId进行推断就为userFactors * itemId = rating value;对userId进行推断就为itemFactors * userId = rating value。
理论推导可见Parallel-ALS推荐算法(factorize-movielens-1M)
Spark ALS代码分析
测试代码
以Spark中的ALSExample为例:
object ALSExample { // $example on$ case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long) def parseRating(str: String): Rating = { val fields = str.split("::") assert(fields.size == 4) Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong) } // $example off$ def main(args: Array[String]) { val spark = SparkSession .builder .appName("ALSExample").master("local") .getOrCreate() import spark.implicits._ // $example on$ //数据格式为: //userId::itemId::rating::timeStamp //1::85::3::1424380312 val ratings = spark.read.textFile("data/mllib/als/sample_movielens_ratings.txt") .map(parseRating) .toDF() val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2))//对数据进行分割,80%为训练样例,剩下的为测试样例。 // Build the recommendation model using ALS on the training data val als = new ALS() .setMaxIter(5)//迭代次数,最大值好像不能>=30,否则会Java Stack Overflow 错误。 .setRegParam(0.01)//正则化参数,使每次迭代平滑一些,此数据集取0.1好像错误率低一些。 .setUserCol("userId") .setItemCol("movieId") .setRatingCol("rating") val model = als.fit(training)//调用算法开始训练 // Evaluate the model by computing the RMSE on the test data val predictions = model.transform(test)//对测试数据进行预测 val evaluator = new RegressionEvaluator() .setMetricName("rmse") .setLabelCol("rating") .setPredictionCol("prediction") val rmse = evaluator.evaluate(predictions)//计算出错误率 println(s"Root-mean-square error = $rmse") // $example off$ spark.stop() } } |
训练数据
override def fit(dataset: Dataset[_]): ALSModel = { transformSchema(dataset.schema) import dataset.sparkSession.implicits._ val r = if ($(ratingCol) != "") col($(ratingCol)).cast(FloatType) else lit(1.0f) val ratings = dataset .select(checkedCast(col($(userCol)).cast(DoubleType)), checkedCast(col($(itemCol)).cast(DoubleType)), r) .rdd .map { row => Rating(row.getInt(0), row.getInt(1), row.getFloat(2)) } val instrLog = Instrumentation.create(this, ratings) instrLog.logParams(rank, numUserBlocks, numItemBlocks, implicitPrefs, alpha, userCol, itemCol, ratingCol, predictionCol, maxIter, regParam, nonnegative, checkpointInterval, seed) val (userFactors, itemFactors) = ALS.train(ratings, rank = $(rank), numUserBlocks = $(numUserBlocks), numItemBlocks = $(numItemBlocks), maxIter = $(maxIter), regParam = $(regParam), implicitPrefs = $(implicitPrefs), alpha = $(alpha), nonnegative = $(nonnegative), intermediateRDDStorageLevel = StorageLevel.fromString($(intermediateStorageLevel)), finalRDDStorageLevel = StorageLevel.fromString($(finalStorageLevel)), checkpointInterval = $(checkpointInterval), seed = $(seed)) val userDF = userFactors.toDF("id", "features") val itemDF = itemFactors.toDF("id", "features") val model = new ALSModel(uid, $(rank), userDF, itemDF).setParent(this) instrLog.logSuccess(model) copyValues(model) } |
def train[ID: ClassTag]( // scalastyle:ignore ratings: RDD[Rating[ID]], rank: Int = 10, numUserBlocks: Int = 10, numItemBlocks: Int = 10, maxIter: Int = 10, regParam: Double = 1.0, implicitPrefs: Boolean = false, alpha: Double = 1.0, nonnegative: Boolean = false, intermediateRDDStorageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK, finalRDDStorageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK, checkpointInterval: Int = 10, seed: Long = 0L)( implicit ord: Ordering[ID]): (RDD[(ID, Array[Float])], RDD[(ID, Array[Float])]) = { require(!ratings.isEmpty(), s"No ratings available from $ratings") require(intermediateRDDStorageLevel != StorageLevel.NONE, "ALS is not designed to run without persisting intermediate RDDs.") val sc = ratings.sparkContext //ALSPartitioner对数据进行分区,这儿分成10个 val userPart = new ALSPartitioner(numUserBlocks) val itemPart = new ALSPartitioner(numItemBlocks) //LocalIndexEncoder封装id值,并计算对应的blockId和localIndex, //这儿由于是10个block,所以所有id的个位对应着blockId,其它的构成localIndex。 //比如,id 25的blockId为5,localIndex为2。 val userLocalIndexEncoder = new LocalIndexEncoder(userPart.numPartitions) val itemLocalIndexEncoder = new LocalIndexEncoder(itemPart.numPartitions) val solver = if (nonnegative) new NNLSSolver else new CholeskySolver val blockRatings = partitionRatings(ratings, userPart, itemPart) .persist(intermediateRDDStorageLevel) val (userInBlocks, userOutBlocks) = makeBlocks("user", blockRatings, userPart, itemPart, intermediateRDDStorageLevel) // materialize blockRatings and user blocks userOutBlocks.count() //swappedBlockRatings的计算结果如图1中的第一个图。 val swappedBlockRatings = blockRatings.map { case ((userBlockId, itemBlockId), RatingBlock(userIds, itemIds, localRatings)) => ((itemBlockId, userBlockId), RatingBlock(itemIds, userIds, localRatings)) } //itemInBlocks的计算结果如图1中的第二个图,itemOutBlocks的计算结果如图1中的第三个图。具体见“In Blocks 和Out Blocks的构造”节。 val (itemInBlocks, itemOutBlocks) = makeBlocks("item", swappedBlockRatings, itemPart, userPart, intermediateRDDStorageLevel) // materialize item blocks itemOutBlocks.count() val seedGen = new XORShiftRandom(seed) var userFactors = initialize(userInBlocks, rank, seedGen.nextLong()) //对每个itemId随机的生成rank(10)个factors var itemFactors = initialize(itemInBlocks, rank, seedGen.nextLong()) var previousCheckpointFile: Option[String] = None val shouldCheckpoint: Int => Boolean = (iter) => sc.checkpointDir.isDefined && checkpointInterval != -1 && (iter % checkpointInterval == 0) val deletePreviousCheckpointFile: () => Unit = () => previousCheckpointFile.foreach { file => try { val checkpointFile = new Path(file) checkpointFile.getFileSystem(sc.hadoopConfiguration).delete(checkpointFile, true) } catch { case e: IOException => logWarning(s"Cannot delete checkpoint file $file:", e) } } if (implicitPrefs) { for (iter <- 1 to maxIter) { userFactors.setName(s"userFactors-$iter").persist(intermediateRDDStorageLevel) val previousItemFactors = itemFactors itemFactors = computeFactors(userFactors, userOutBlocks, itemInBlocks, rank, regParam, userLocalIndexEncoder, implicitPrefs, alpha, solver) previousItemFactors.unpersist() itemFactors.setName(s"itemFactors-$iter").persist(intermediateRDDStorageLevel) // TODO: Generalize PeriodicGraphCheckpointer and use it here. val deps = itemFactors.dependencies if (shouldCheckpoint(iter)) { itemFactors.checkpoint() // itemFactors gets materialized in computeFactors } val previousUserFactors = userFactors userFactors = computeFactors(itemFactors, itemOutBlocks, userInBlocks, rank, regParam, itemLocalIndexEncoder, implicitPrefs, alpha, solver) if (shouldCheckpoint(iter)) { ALS.cleanShuffleDependencies(sc, deps) deletePreviousCheckpointFile() previousCheckpointFile = itemFactors.getCheckpointFile } previousUserFactors.unpersist() } } else { //迭代依次交换计算出itemFactors和userFactors,具体见“计算factors”节。 for (iter <- 0 until maxIter) { itemFactors = computeFactors(userFactors, userOutBlocks, itemInBlocks, rank, regParam, userLocalIndexEncoder, solver = solver) if (shouldCheckpoint(iter)) { val deps = itemFactors.dependencies itemFactors.checkpoint() itemFactors.count() // checkpoint item factors and cut lineage ALS.cleanShuffleDependencies(sc, deps) deletePreviousCheckpointFile() previousCheckpointFile = itemFactors.getCheckpointFile } //如图7。 userFactors = computeFactors(itemFactors, itemOutBlocks, userInBlocks, rank, regParam, itemLocalIndexEncoder, solver = solver) } } val userIdAndFactors = userInBlocks .mapValues(_.srcIds) .join(userFactors) .mapPartitions({ items => items.flatMap { case (_, (ids, factors)) => ids.view.zip(factors) } // Preserve the partitioning because IDs are consistent with the partitioners in userInBlocks // and userFactors. }, preservesPartitioning = true) .setName("userFactors") .persist(finalRDDStorageLevel) val itemIdAndFactors = itemInBlocks .mapValues(_.srcIds) .join(itemFactors) .mapPartitions({ items => items.flatMap { case (_, (ids, factors)) => ids.view.zip(factors) } }, preservesPartitioning = true) .setName("itemFactors") .persist(finalRDDStorageLevel) if (finalRDDStorageLevel != StorageLevel.NONE) { userIdAndFactors.count() itemFactors.unpersist() itemIdAndFactors.count() userInBlocks.unpersist() userOutBlocks.unpersist() itemInBlocks.unpersist() itemOutBlocks.unpersist() blockRatings.unpersist() } //计算出的factors,见图8。 (userIdAndFactors, itemIdAndFactors) } |
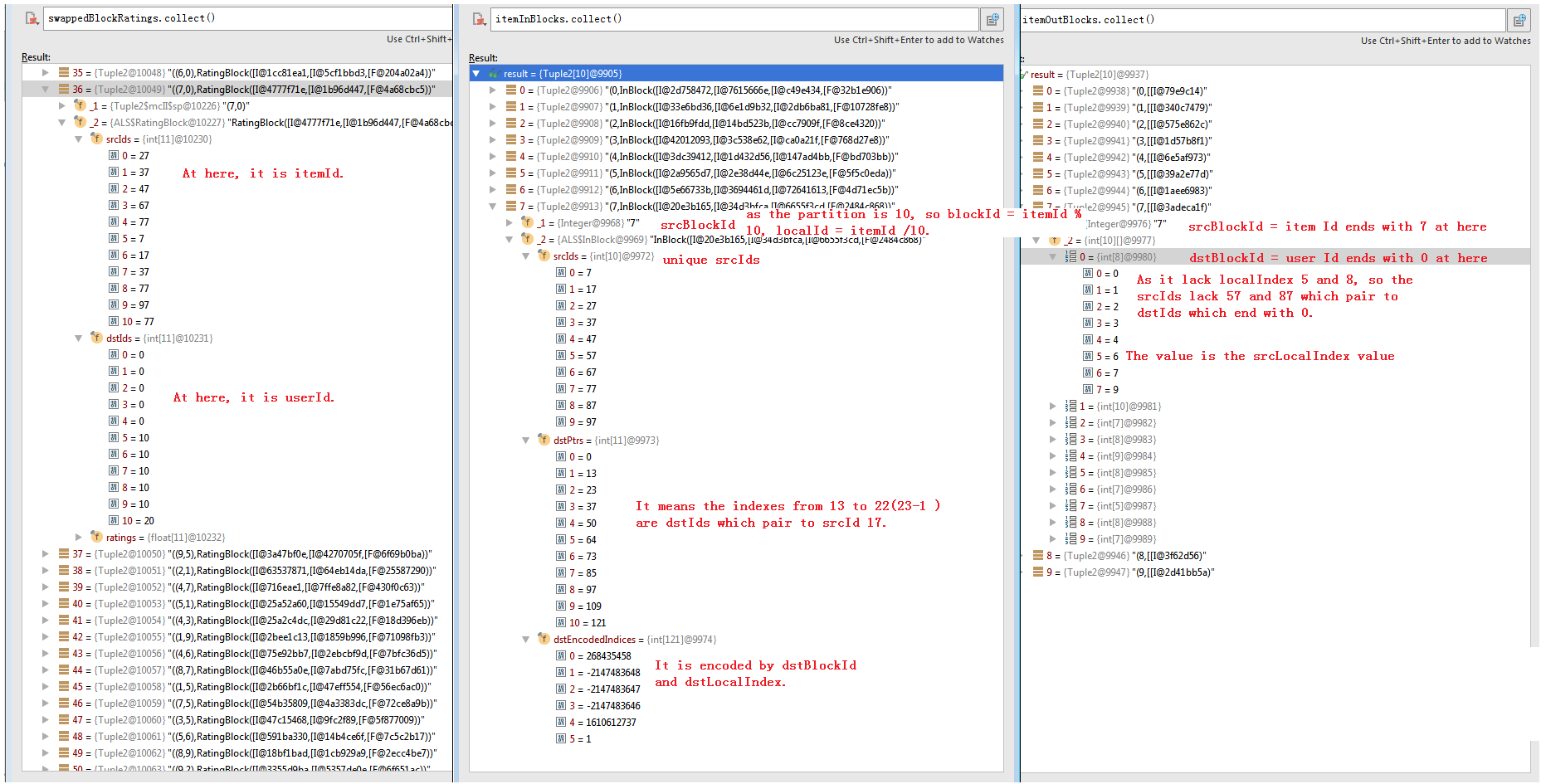
图1 Block Rating, Item In Block, Item Out Block
In Blocks 和Out Blocks的构造
private def makeBlocks[ID: ClassTag]( prefix: String, ratingBlocks: RDD[((Int, Int), RatingBlock[ID])], srcPart: Partitioner, dstPart: Partitioner, storageLevel: StorageLevel)( implicit srcOrd: Ordering[ID]): (RDD[(Int, InBlock[ID])], RDD[(Int, OutBlock)]) = { val inBlocks = ratingBlocks.map { case ((srcBlockId, dstBlockId), RatingBlock(srcIds, dstIds, ratings)) => // The implementation is a faster version of // val dstIdToLocalIndex = dstIds.toSet.toSeq.sorted.zipWithIndex.toMap val start = System.nanoTime() //计算每个dstId在每个block中的localIndex。如6为0;16为1;26为2。见图2第一个图。 val dstIdSet = new OpenHashSet[ID](1 << 20) dstIds.foreach(dstIdSet.add) val sortedDstIds = new Array[ID](dstIdSet.size) var i = 0 var pos = dstIdSet.nextPos(0) while (pos != -1) { sortedDstIds(i) = dstIdSet.getValue(pos) pos = dstIdSet.nextPos(pos + 1) i += 1 } assert(i == dstIdSet.size) Sorting.quickSort(sortedDstIds) val dstIdToLocalIndex = new OpenHashMap[ID, Int](sortedDstIds.length) i = 0 while (i < sortedDstIds.length) { dstIdToLocalIndex.update(sortedDstIds(i), i) i += 1 } logDebug( "Converting to local indices took " + (System.nanoTime() - start) / 1e9 + " seconds.") val dstLocalIndices = dstIds.map(dstIdToLocalIndex.apply) (srcBlockId, (dstBlockId, srcIds, dstLocalIndices, ratings)) }.groupByKey(new ALSPartitioner(srcPart.numPartitions)) .mapValues { iter => val builder = new UncompressedInBlockBuilder[ID](new LocalIndexEncoder(dstPart.numPartitions)) iter.foreach { case (dstBlockId, srcIds, dstLocalIndices, ratings) => builder.add(dstBlockId, srcIds, dstLocalIndices, ratings) } //这儿会对相同的srcId进行排序压缩。压缩前见图3第一个图,压缩后见图3第二个图。其中dstPtrs记录每个srcId对应的dstId在dstEncodeIndices里面的Index区间。 builder.build().compress() }.setName(prefix + "InBlocks") .persist(storageLevel) val outBlocks = inBlocks.mapValues { case InBlock(srcIds, dstPtrs, dstEncodedIndices, ratings) => val encoder = new LocalIndexEncoder(dstPart.numPartitions) val activeIds = Array.fill(dstPart.numPartitions)(mutable.ArrayBuilder.make[Int]) var i = 0 val seen = new Array[Boolean](dstPart.numPartitions) while (i < srcIds.length) { var j = dstPtrs(i) ju.Arrays.fill(seen, false) while (j < dstPtrs(i + 1)) { val dstBlockId = encoder.blockId(dstEncodedIndices(j)) var localIndex = encoder.localIndex(dstEncodedIndices(j)) var rating = ratings(0) if (!seen(dstBlockId)) { activeIds(dstBlockId) += i // add the local index in this out-block seen(dstBlockId) = true } j += 1 } i += 1 } //记录当前dstBlockId(userBlockId)所对应的dstIds(itemId)中有关联的localIndice。即去掉无关联的。 activeIds.map { x => x.result() } }.setName(prefix + "OutBlocks") .persist(storageLevel) (inBlocks, outBlocks) } |
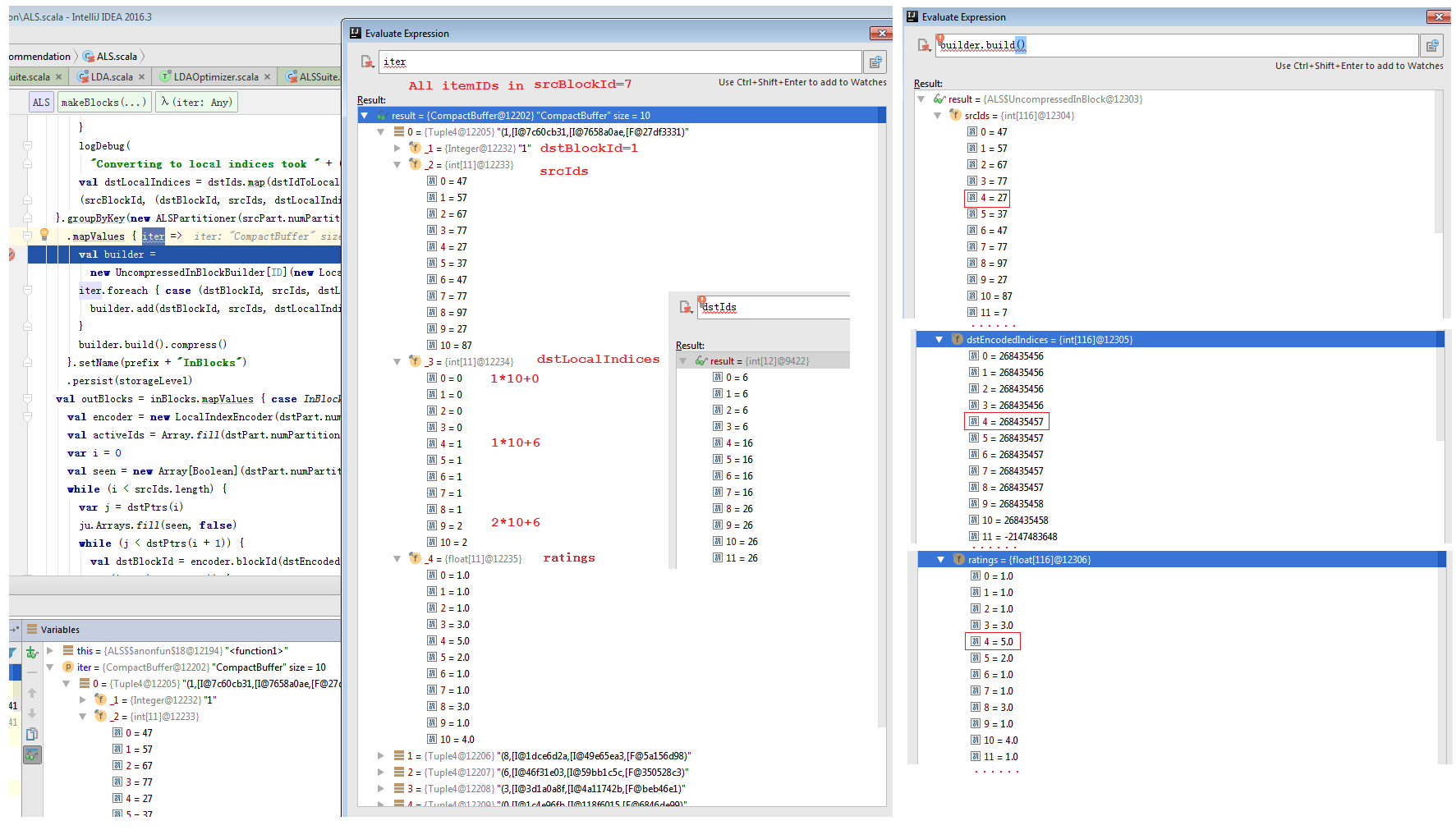
图2 In Blocks 1
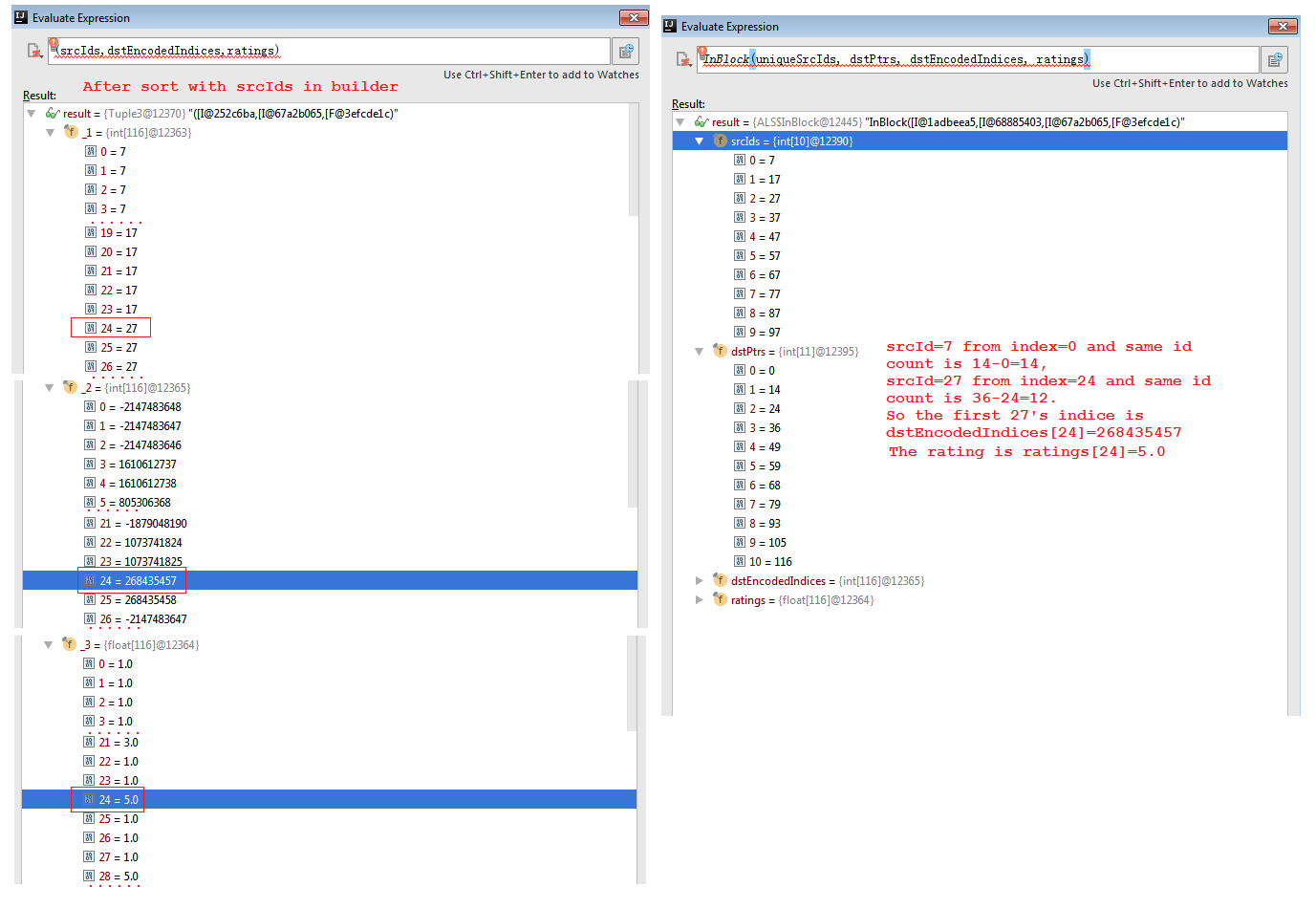
图3 In Blocks 2
计算factors
private def computeFactors[ID]( srcFactorBlocks: RDD[(Int, FactorBlock)], srcOutBlocks: RDD[(Int, OutBlock)], dstInBlocks: RDD[(Int, InBlock[ID])], rank: Int, regParam: Double, srcEncoder: LocalIndexEncoder, implicitPrefs: Boolean = false, alpha: Double = 1.0, solver: LeastSquaresNESolver): RDD[(Int, FactorBlock)] = { val numSrcBlocks = srcFactorBlocks.partitions.length val YtY = if (implicitPrefs) Some(computeYtY(srcFactorBlocks, rank)) else None //计算srcOut的过程如图4。 val srcOut = srcOutBlocks.join(srcFactorBlocks).flatMap { case (srcBlockId, (srcOutBlock, srcFactors)) => srcOutBlock.view.zipWithIndex.map { case (activeIndices, dstBlockId) => (dstBlockId, (srcBlockId, activeIndices.map(idx => srcFactors(idx)))) } } //如图5。 val merged = srcOut.groupByKey(new ALSPartitioner(dstInBlocks.partitions.length)) dstInBlocks.join(merged).mapValues { case (InBlock(dstIds, srcPtrs, srcEncodedIndices, ratings), srcFactors) => val sortedSrcFactors = new Array[FactorBlock](numSrcBlocks) srcFactors.foreach { case (srcBlockId, factors) => sortedSrcFactors(srcBlockId) = factors } val dstFactors = new Array[Array[Float]](dstIds.length) var j = 0 val ls = new NormalEquation(rank) while (j < dstIds.length) { ls.reset() if (implicitPrefs) { ls.merge(YtY.get) } var i = srcPtrs(j) var numExplicits = 0 while (i < srcPtrs(j + 1)) { val encoded = srcEncodedIndices(i) val blockId = srcEncoder.blockId(encoded) val localIndex = srcEncoder.localIndex(encoded) val srcFactor = sortedSrcFactors(blockId)(localIndex) val rating = ratings(i) if (implicitPrefs) { // Extension to the original paper to handle b < 0. confidence is a function of |b| // instead so that it is never negative. c1 is confidence - 1.0. val c1 = alpha * math.abs(rating) // For rating <= 0, the corresponding preference is 0. So the term below is only added // for rating > 0. Because YtY is already added, we need to adjust the scaling here. if (rating > 0) { numExplicits += 1 ls.add(srcFactor, (c1 + 1.0) / c1, c1) } } else { ls.add(srcFactor, rating) numExplicits += 1 } i += 1 } // Weight lambda by the number of explicit ratings based on the ALS-WR paper. //如图6 dstFactors(j) = solver.solve(ls, numExplicits * regParam) j += 1 } dstFactors } } |
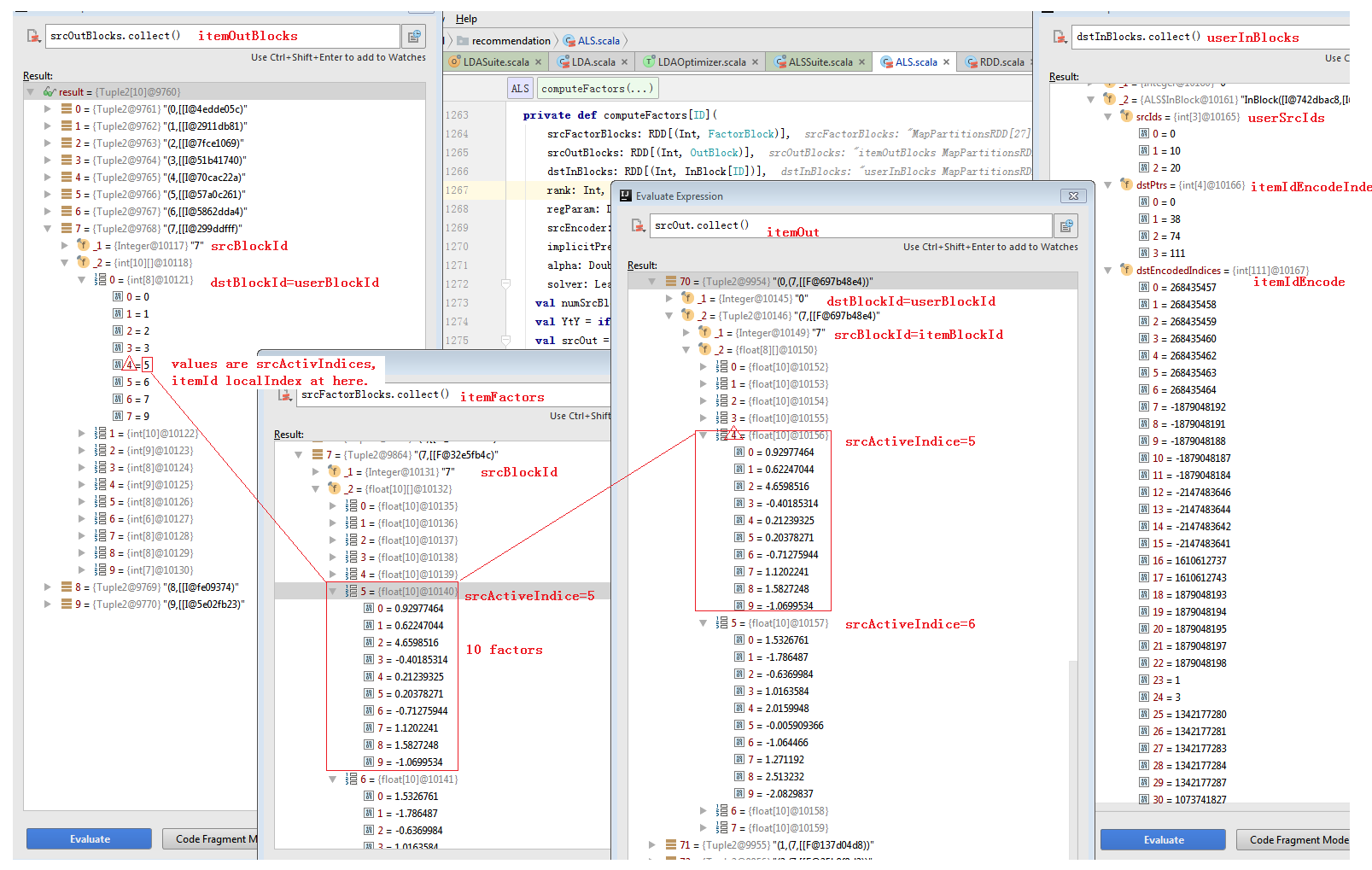
图4 srcOut
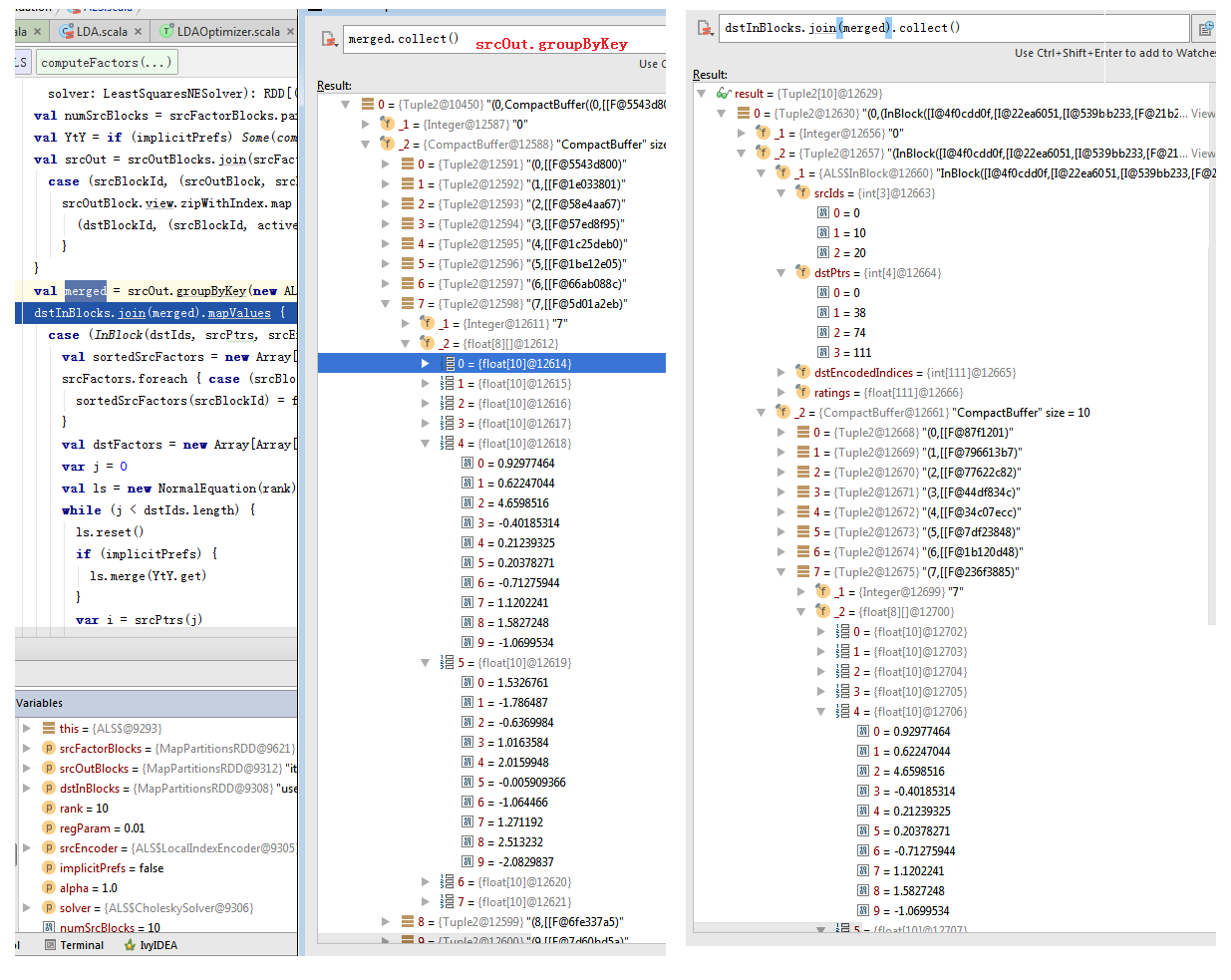
图5 dstInBlocks Join srcOut
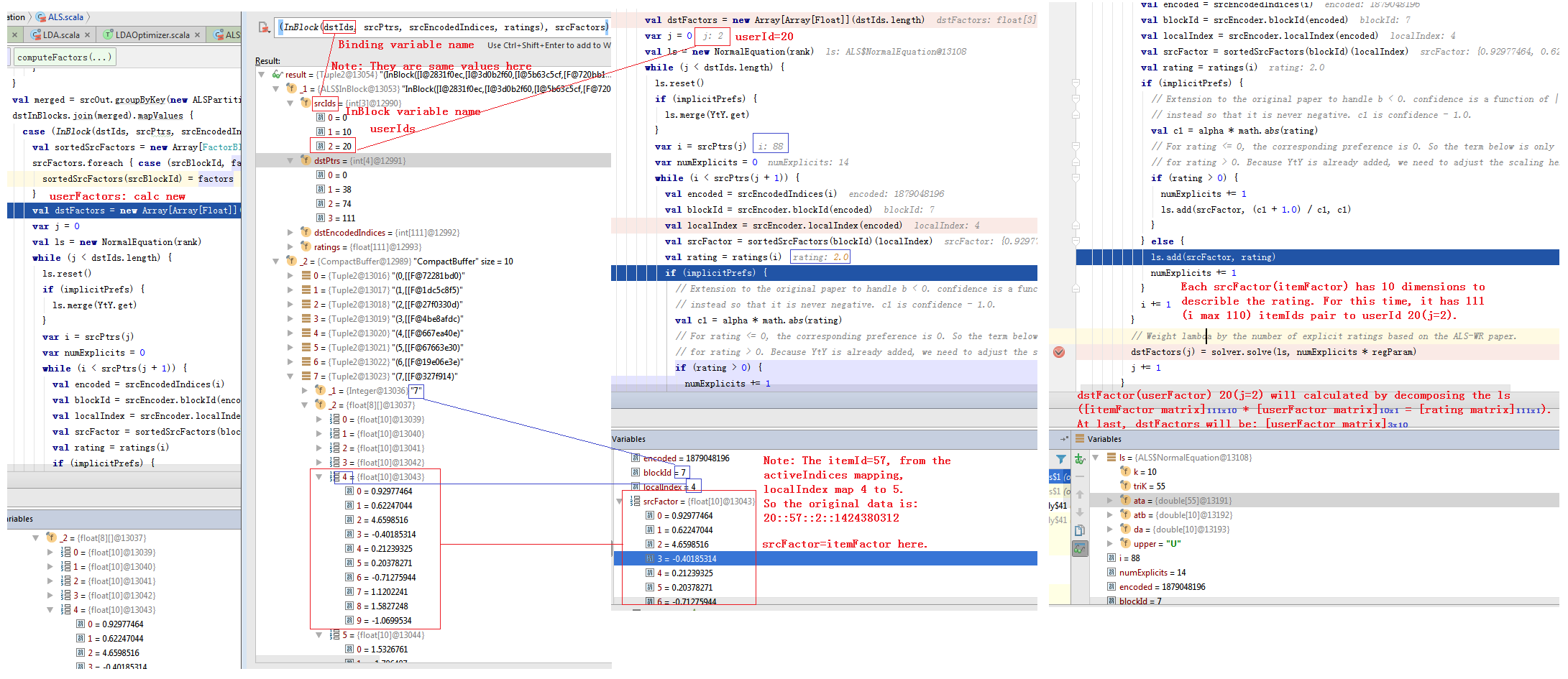
图6 Compute One Single dstFactors

图7 Computed Total dstFactors
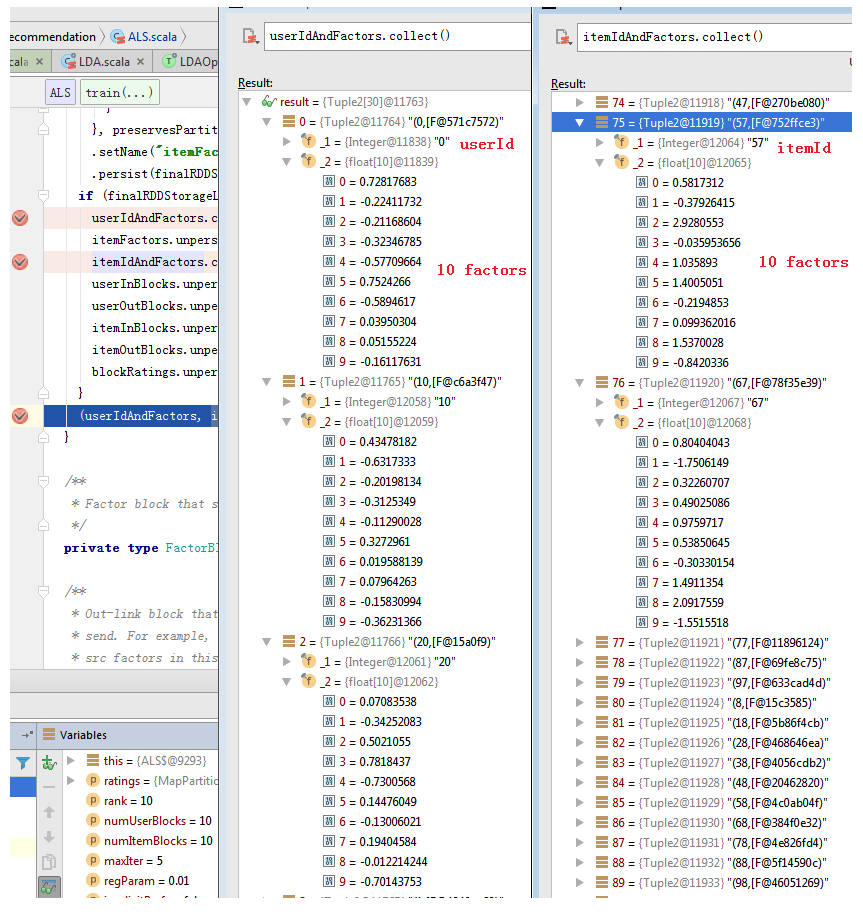
图8 Training Result
测试数据
override def transform(dataset: Dataset[_]): DataFrame = { transformSchema(dataset.schema) // Register a UDF for DataFrame, and then // create a new column named map(predictionCol) by running the predict UDF. val predict = udf { (userFeatures: Seq[Float], itemFeatures: Seq[Float]) => if (userFeatures != null && itemFeatures != null) { blas.sdot(rank, userFeatures.toArray, 1, itemFeatures.toArray, 1) } else { Float.NaN } } //图9阐述了此计算过程。 dataset .join(userFactors, checkedCast(dataset($(userCol)).cast(DoubleType)) === userFactors("id"), "left") .join(itemFactors, checkedCast(dataset($(itemCol)).cast(DoubleType)) === itemFactors("id"), "left") .select(dataset("*"), predict(userFactors("features"), itemFactors("features")).as($(predictionCol))) } |
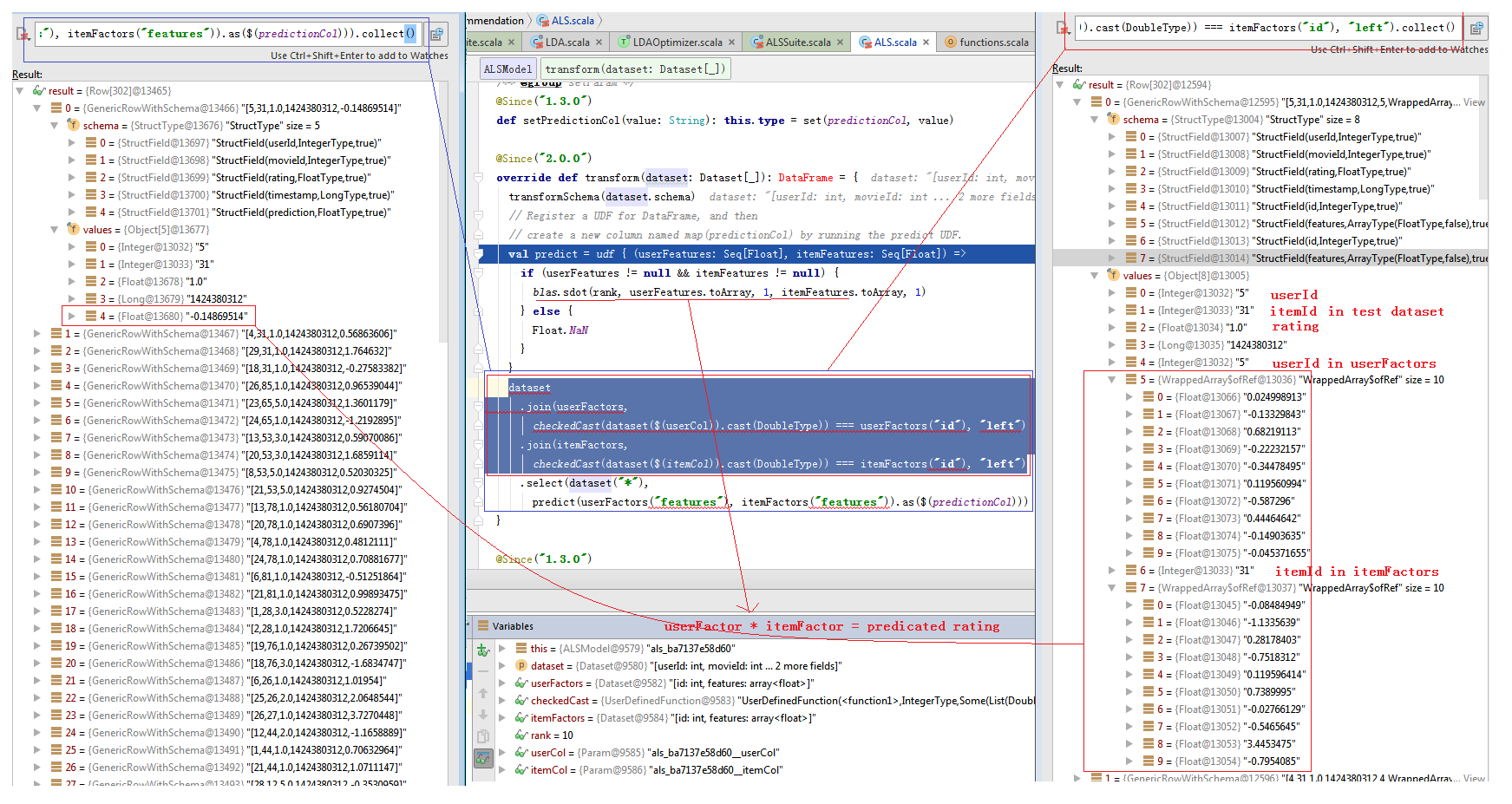
图9 Predict The Rating With Test Data
本作品采用知识共享署名 4.0 国际许可协议进行许可。