The Spark Planner is the bridge from Logic Plan to Spark Plan which will convert Logic Plan to Spark Plan.
The SparkPlanner extends from SparkStrategies(Code in SparkStrategies.scala).
It have several strategies:
def strategies: Seq[Strategy] =
extraStrategies ++ (
FileSourceStrategy ::
DataSourceStrategy ::
DDLStrategy ::
SpecialLimits ::
Aggregation ::
JoinSelection ::
InMemoryScans ::
BasicOperators :: Nil) |
def strategies: Seq[Strategy] =
extraStrategies ++ (
FileSourceStrategy ::
DataSourceStrategy ::
DDLStrategy ::
SpecialLimits ::
Aggregation ::
JoinSelection ::
InMemoryScans ::
BasicOperators :: Nil)
Let me introduce several here:
SpecialLimits
The Logical Plan Limit will be converted to Spark Plan TakeOrderedAndProjectExec here.
/**
* Plans special cases of limit operators.
*/
object SpecialLimits extends Strategy {
override def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case logical.ReturnAnswer(rootPlan) => rootPlan match {
case logical.Limit(IntegerLiteral(limit), logical.Sort(order, true, child)) =>
execution.TakeOrderedAndProjectExec(limit, order, child.output, planLater(child)) :: Nil
case logical.Limit(
IntegerLiteral(limit),
logical.Project(projectList, logical.Sort(order, true, child))) =>
execution.TakeOrderedAndProjectExec(
limit, order, projectList, planLater(child)) :: Nil
case logical.Limit(IntegerLiteral(limit), child) =>
execution.CollectLimitExec(limit, planLater(child)) :: Nil
case other => planLater(other) :: Nil
}
case logical.Limit(IntegerLiteral(limit), logical.Sort(order, true, child)) =>
execution.TakeOrderedAndProjectExec(limit, order, child.output, planLater(child)) :: Nil
case logical.Limit(
IntegerLiteral(limit), logical.Project(projectList, logical.Sort(order, true, child))) =>
execution.TakeOrderedAndProjectExec(
limit, order, projectList, planLater(child)) :: Nil
case _ => Nil
}
} |
/**
* Plans special cases of limit operators.
*/
object SpecialLimits extends Strategy {
override def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case logical.ReturnAnswer(rootPlan) => rootPlan match {
case logical.Limit(IntegerLiteral(limit), logical.Sort(order, true, child)) =>
execution.TakeOrderedAndProjectExec(limit, order, child.output, planLater(child)) :: Nil
case logical.Limit(
IntegerLiteral(limit),
logical.Project(projectList, logical.Sort(order, true, child))) =>
execution.TakeOrderedAndProjectExec(
limit, order, projectList, planLater(child)) :: Nil
case logical.Limit(IntegerLiteral(limit), child) =>
execution.CollectLimitExec(limit, planLater(child)) :: Nil
case other => planLater(other) :: Nil
}
case logical.Limit(IntegerLiteral(limit), logical.Sort(order, true, child)) =>
execution.TakeOrderedAndProjectExec(limit, order, child.output, planLater(child)) :: Nil
case logical.Limit(
IntegerLiteral(limit), logical.Project(projectList, logical.Sort(order, true, child))) =>
execution.TakeOrderedAndProjectExec(
limit, order, projectList, planLater(child)) :: Nil
case _ => Nil
}
}
Aggregation
The Logical Plan Aggregate will be convert to bellow Spark Plan based on conditions:
SortAggregateExec
HashAggregateExec
ObjectHashAggregateExec
/**
* Used to plan the aggregate operator for expressions based on the AggregateFunction2 interface.
*/
object Aggregation extends Strategy {
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case PhysicalAggregation(
groupingExpressions, aggregateExpressions, resultExpressions, child) =>
val (functionsWithDistinct, functionsWithoutDistinct) =
aggregateExpressions.partition(_.isDistinct)
...... |
/**
* Used to plan the aggregate operator for expressions based on the AggregateFunction2 interface.
*/
object Aggregation extends Strategy {
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case PhysicalAggregation(
groupingExpressions, aggregateExpressions, resultExpressions, child) =>
val (functionsWithDistinct, functionsWithoutDistinct) =
aggregateExpressions.partition(_.isDistinct)
......
Let me use SQL “SELECT x.str, COUNT(*) FROM df x JOIN df y ON x.str = y.str GROUP BY x.str” for example.
And at here, “COUNT(*)” is an aggregate expression.
继续阅读“Spark Planner for Converting Logical Plan to Spark Plan”本作品采用知识共享署名 4.0 国际许可协议进行许可。
 第k次迭代为:
第k次迭代为:![\[ m_k(p)=f_k + \nabla f_k^T p+\frac{1}{2} p^T B_k p \qquad\qquad\qquad Equitation 1 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-d1060385dc1a33ec7865560a5fae76ef_l3.png "Rendered by QuickLaTeX.com")
 为n x n对称正定矩阵,可以在每次迭代中更新。注意到这个构造函数在p=0的时候,
为n x n对称正定矩阵,可以在每次迭代中更新。注意到这个构造函数在p=0的时候, 和
和 和原函数是相同的。对其求导,得到
和原函数是相同的。对其求导,得到![\[ p_k= - B_k^{-1} \nabla f_k \qquad\qquad\qquad Equitation 2 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-b49c9e17e378c2745ec30ca957681ed0_l3.png "Rendered by QuickLaTeX.com")
 第k+1次迭代为(其中
第k+1次迭代为(其中 可以用强Wolfe准则来计算):
可以用强Wolfe准则来计算):![\[ x_{k+1}= x_k + \alpha_k p_k \qquad\qquad\qquad Equitation 3 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-5d87d1796b214da34d89d90747aa6887_l3.png "Rendered by QuickLaTeX.com")
![\[ m_{k+1}(p)=f_{k+1} + \nabla f_{k+1}^T p+\frac{1}{2} p^T B_{k+1} p \qquad\qquad\qquad Equitation 4 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-6984d2187c63c5f0b03c9852e3410a09_l3.png "Rendered by QuickLaTeX.com")
 呢?函数
呢?函数 应该在
应该在 导数一致。对其求导,并令
导数一致。对其求导,并令 ,即
,即 )
)![\[ \nabla m_{k+1}( - \alpha_k p_k )= \nabla f_{k+1} - \alpha_k B_{k+1} p_k = \nabla f_k \qquad\qquad\qquad Equitation 5 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-31e649a173029279a7b1c43d89f60637_l3.png "Rendered by QuickLaTeX.com")
![\[ B_{k+1} \alpha_k p_k = \nabla f_{k+1} - \nabla f_k \qquad\qquad\qquad Equitation 6 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-4db45036c89babeba307a16076258377_l3.png "Rendered by QuickLaTeX.com")
 ,方程6为:
,方程6为:![\[ B_{k+1} s_k = y_k \qquad\qquad\qquad Equitation 7 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-16a47524446a020f8c68cb2b80f1ceda_l3.png "Rendered by QuickLaTeX.com")
 ,得到另一个形式:
,得到另一个形式:![\[ H_{k+1} y_k = s_k \qquad\qquad\qquad Equitation 8 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-0d6f3e544c82c49fe67d2691f3f42348_l3.png "Rendered by QuickLaTeX.com")
![\[ p_k= - H_k \nabla f_k \qquad\qquad\qquad Equitation 9 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-15faa30f2e63791ca7b1dce07db6cb2c_l3.png "Rendered by QuickLaTeX.com")
![\[ B_{k+1}= B_k + E_k , H_{k+1}= H_k + D_k \qquad\qquad\qquad Equitation 10 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-39de6f917f917e77328512c325ab2906_l3.png "Rendered by QuickLaTeX.com")
 和
和 为秩1或秩2的矩阵。
为秩1或秩2的矩阵。![\[ E_k = \alpha u_k u_k^T + \beta v_k v_k^T \qquad\qquad\qquad Equitation 11 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-702b044e2b7728bb406cc8fcba0327af_l3.png "Rendered by QuickLaTeX.com")
![\[ ( B_k + \alpha u_k u_k^T + \beta v_k v_k^T )s_k = y_k \qquad\qquad\qquad Equitation 12 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-0c12c30228690068a662e7b5635240bd_l3.png "Rendered by QuickLaTeX.com")
![\[ \alpha ( u_k^T s_k ) u_k + \beta ( v_k^T s_k ) v_k = y_k - B_k s_k \qquad\qquad\qquad Equitation 13 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-a12d88b484e83de57c8d40ca2b9cdca0_l3.png "Rendered by QuickLaTeX.com")
 和
和 不唯一,令
不唯一,令 和
和 ,即
,即 和
和 ,带入方程11得:
,带入方程11得:![\[ E_k = \alpha \gamma^2 B_k s_k s_k^T B_k + \beta \theta^2 y_k y_k^T \qquad\qquad\qquad Equitation 14 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-0441bdf028d372c9fec243fcc0e785d0_l3.png "Rendered by QuickLaTeX.com")
![\[ \alpha ( (\gamma B_k s_k)^T s_k ) (\gamma B_k s_k) + \beta ( (\theta y_k)^T s_k ) (\theta y_k) = y_k - B_k s_k \qquad\qquad\qquad Equitation 15 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-ff38b699c2974b30483427deb538fb58_l3.png "Rendered by QuickLaTeX.com")
![\[ [ \alpha \gamma^2 (s_k^T B_k s_k) + 1 ]B_k s_k + [\beta \theta^2 (y_k^T s) - 1 ]y_k = 0 \qquad\qquad\qquad Equitation 16 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-42318c26ddc4f1caa2df118d6c209bed_l3.png "Rendered by QuickLaTeX.com")
 ,
, ,
, ,
, 。
。![\[ B_{k+1} = B_k - \frac{B_k s_k s_k^T B_k}{s_k^T B_k s_k} + \frac{y_k y_k^T}{y_k^T s_k} \qquad\qquad\qquad Equitation 17 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-1cceb1e343a1978937fab065edd37652_l3.png "Rendered by QuickLaTeX.com")
![\[ B_{k+1}^{-1} = (B_k - \frac{B_k s_k s_k^T B_k}{s_k^T B_k s_k} + \frac{y_k y_k^T}{y_k^T s_k})^{-1} \qquad\qquad\qquad Equitation 18 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-9b90290cce22b76e862636f1c7e10d2d_l3.png "Rendered by QuickLaTeX.com")
![\[ (A + UCV)^{-1} = A^{-1} - \frac{A^{-1}UVA^{-1}}{C^{-1} + VA^{-1}U} \qquad\qquad\qquad Sherman Morison Woodbury Equitation \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-20a3b37384085495ed92451031d4437a_l3.png "Rendered by QuickLaTeX.com")
 是方程中的
是方程中的
![\[ B_{k+1}^{-1} = (I - \frac{s_k y_k^T}{y_k^T s_k}) B_k^{-1} (I - \frac{y_k s_k^T}{y_k^T s_k}) + \frac{s_k s_k^T}{y_k^T s_k} \qquad\qquad\qquad Equitation 19 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-96e252069fa2cd4fff3d7bd6db3861d8_l3.png "Rendered by QuickLaTeX.com")
 ,方程19可得BFGS方法的迭代方程:
,方程19可得BFGS方法的迭代方程:![\[ H_{k+1} = (I - \rho s_k y_k^T }) H_k (I - \rho y_k s_k^T}) + \rho s_k s_k^T \qquad\qquad\qquad BFGS Equitation \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-1074f808a1ae6215fa48ba562803ae93_l3.png "Rendered by QuickLaTeX.com")
 ,则BFGS方程可写成:
,则BFGS方程可写成:![\[ H_{k+1} = V_k^T H_k V_k + \rho s_k s_k^T \qquad\qquad\qquad Equitation 20 \]](https://liuxiaofei.com.cn/blog/wp-content/ql-cache/quicklatex.com-c514a95ac49f339f139e042444e8c69d_l3.png "Rendered by QuickLaTeX.com")

 需要用到
需要用到 组数据,数据量非常大,LBFGS算法就采取只去最近的m组数据来运算,即可以构造近似计算公式:
组数据,数据量非常大,LBFGS算法就采取只去最近的m组数据来运算,即可以构造近似计算公式:
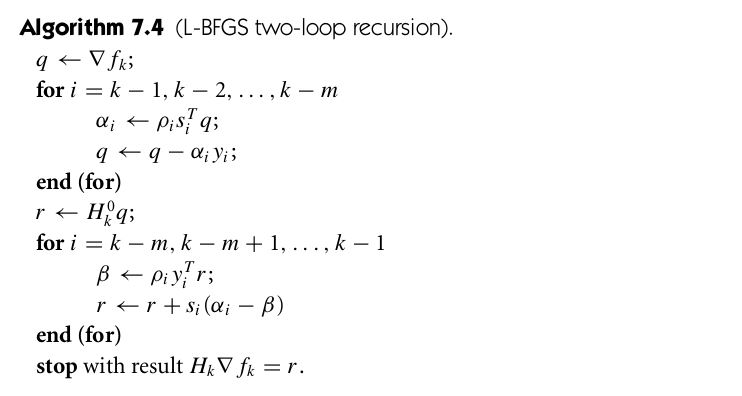
 :
:
 ,这里的m指的是从现在到历史记录m次的后一次,因为LBFGS只记录m次历史:
,这里的m指的是从现在到历史记录m次的后一次,因为LBFGS只记录m次历史: