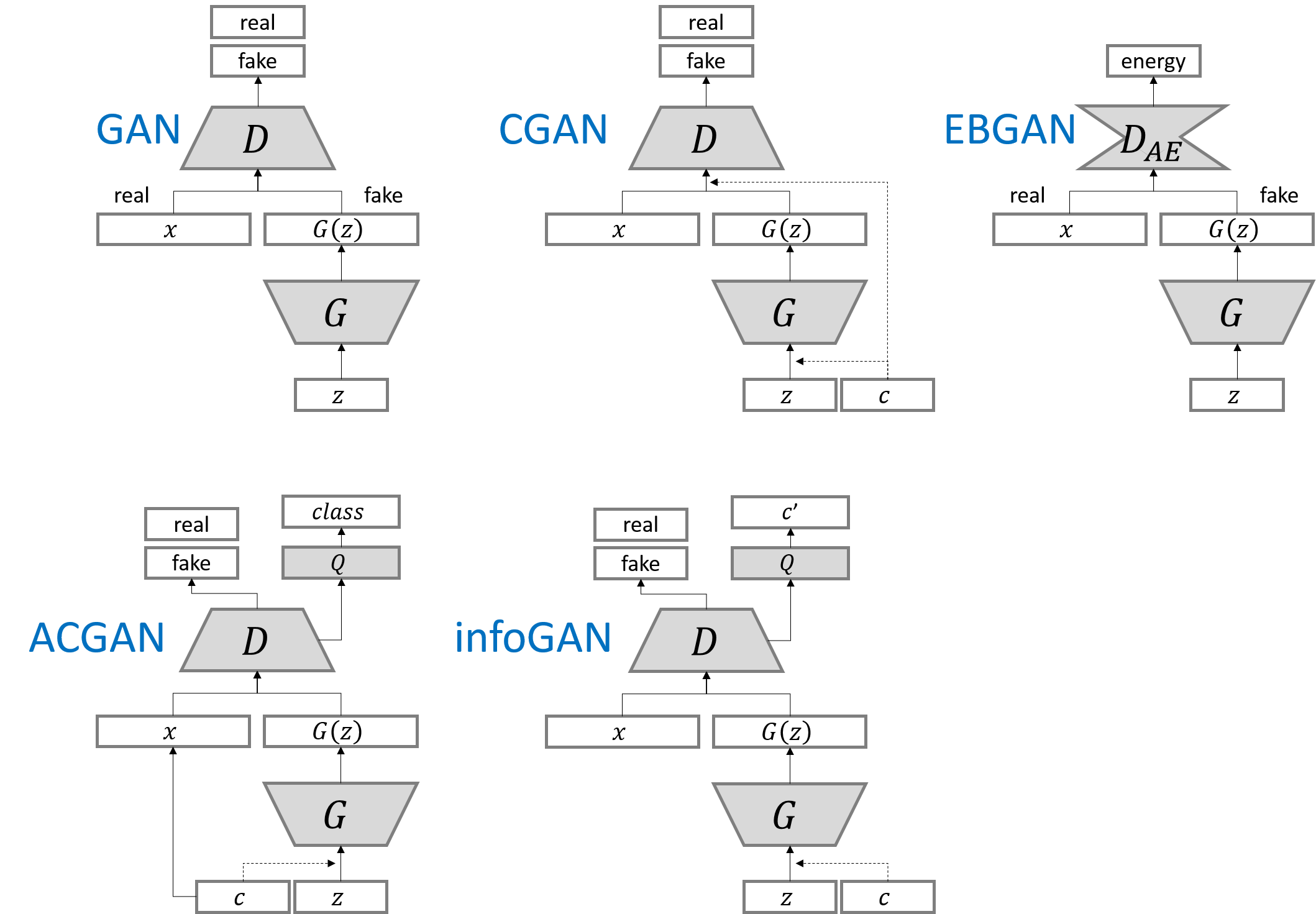
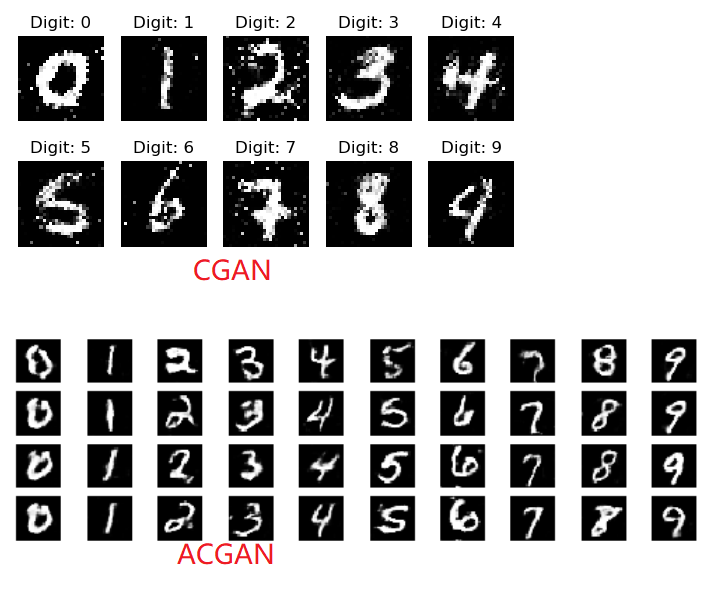
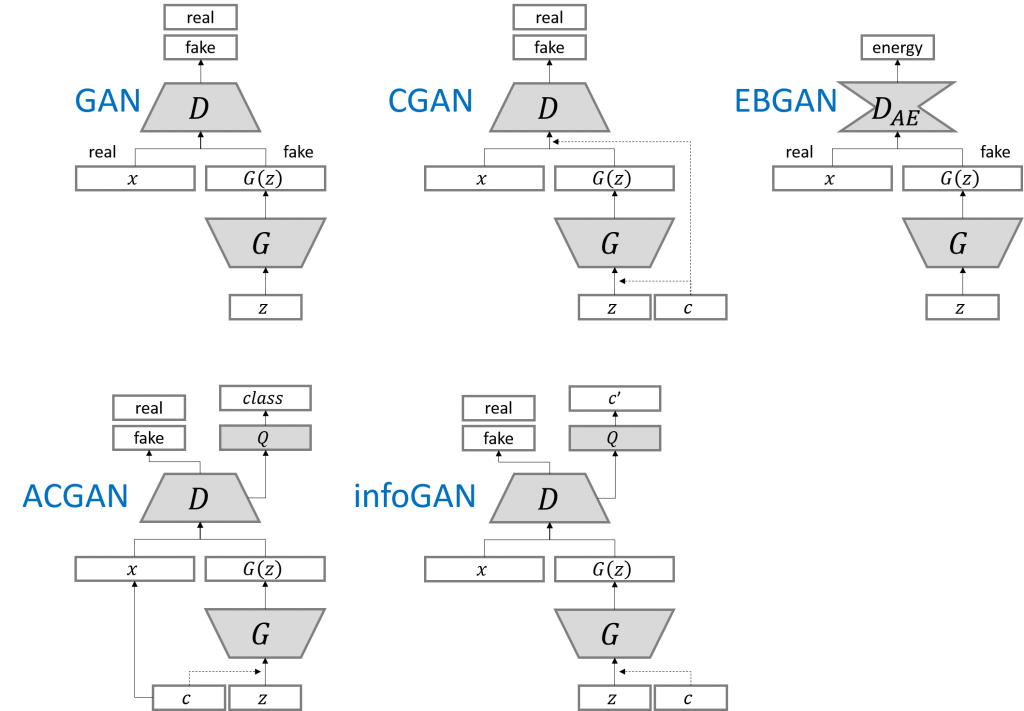
CGAN与GAN的区别如下
GAN视频讲解参考
CGAN视频讲解参考
在生成网络的输入和鉴别网络的输入都混入label,这样生成网络就会学会根据label生成含有label特征的图片;鉴别网络就能学会根据label快速学会分类图片。
如下生成网络model不直接传入noise,而是传入noise和label对于元素相乘的结果。
label[1,]->Embedding[10,100]->label_embedding[1,100]->Flatten[100,] X Noise[100,] = model_input[100,]
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input) |
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
继续阅读“CGAN与GAN的区别”本作品采用知识共享署名 4.0 国际许可协议进行许可。