原创文章,转载请注明: 转载自慢慢的回味
本文链接地址: TensorFlow Session的创建
本文介绍TensorFlow Session的创建。TensorFlow使用Session 类来表示客户端程序(通常用Python 程序,但也提供了其他语言的类似接口,这儿就是用C接口)与 C++ 运行时之间的连接。Session 对象使我们能够访问本地机器中的设备和使用分布式 TensorFlow 运行时的远程设备。它还可缓存关于Graph 的信息,使您能够多次高效地运行同一计算。Session接受Graph参数和Options选项参数,Options参数可以指定使用的设备等信息。
回目录
SessionFactory的创建
在so文件加载的时候,文件direct_session.cc中静态变量registrar的创建会向SessionFactory中注册DIRECT_SESSION类型的factory。
class DirectSessionRegistrar { public: DirectSessionRegistrar() { SessionFactory::Register("DIRECT_SESSION", new DirectSessionFactory()); } }; static DirectSessionRegistrar registrar; |
在so文件加载的时候,文件grpc_session.cc中静态变量registrar的创建会向SessionFactory中注册GRPC_SESSION类型的factory。
class GrpcSessionRegistrar { public: GrpcSessionRegistrar() { SessionFactory::Register("GRPC_SESSION", new GrpcSessionFactory()); } }; static GrpcSessionRegistrar registrar; |
DeviceFactory的创建
在so文件加载的时候,文件threadpool_device_factory.cc中REGISTER_LOCAL_DEVICE_FACTORY宏调用会向DeviceFactory中注册CPU类型的ThreadPoolDeviceFactory。
REGISTER_LOCAL_DEVICE_FACTORY("CPU", ThreadPoolDeviceFactory, 60); |
上面的调用宏展开为:
static ::tensorflow::dfactory::Registrar<ThreadPoolDeviceFactory> ___32__object_("CPU", 60) |
device_factory.h文件中的构造方法dfactory::Registrar完成Factory的注册,这里的new Factory()使用的是模板类里面的class,这儿为ThreadPoolDeviceFactory:
namespace dfactory { template <class Factory> class Registrar { public: ............ explicit Registrar(const string& device_type, int priority = 50) { DeviceFactory::Register(device_type, new Factory(), priority); } }; } |
device_factory.cc文件中的方法DeviceFactory::Register把factory注册到device_factories map中:
void DeviceFactory::Register(const string& device_type, DeviceFactory* factory, int priority) { mutex_lock l(*get_device_factory_lock()); std::unique_ptr<DeviceFactory> factory_ptr(factory); std::unordered_map<string, FactoryItem>& factories = device_factories(); auto iter = factories.find(device_type); if (iter == factories.end()) { factories[device_type] = {std::move(factory_ptr), priority}; } else { if (iter->second.priority < priority) { iter->second = {std::move(factory_ptr), priority}; } else if (iter->second.priority == priority) { LOG(FATAL) << "Duplicate registration of device factory for type " << device_type << " with the same priority " << priority; } } } |
同理,如果支持GPU,文件gpu_device_factory.cc中REGISTER_LOCAL_DEVICE_FACTORY宏调用会向DeviceFactory中注册GPU类型的GPUDeviceFactory和与GPU兼容的CPU类型的GPUCompatibleCPUDeviceFactory。
REGISTER_LOCAL_DEVICE_FACTORY("GPU", GPUDeviceFactory, 210); REGISTER_LOCAL_DEVICE_FACTORY("CPU", GPUCompatibleCPUDeviceFactory, 70); |
Session的创建
主程序通过调用c api TF_NewSession创建Session:
TF_SessionOptions* opts = TF_NewSessionOptions(); TF_Session* sess = TF_NewSession(graph, opts, s); |
c_api.cc中的TF_NewSession方法创建底层session并把其和graph绑定在new_session上:
TF_Session::TF_Session(tensorflow::Session* s, TF_Graph* g) : session(s), graph(g), last_num_graph_nodes(0), extend_before_run(true) {} TF_Session* TF_NewSession(TF_Graph* graph, const TF_SessionOptions* opt, TF_Status* status) { Session* session; status->status = NewSession(opt->options, &session); if (TF_GetCode(status) == TF_OK) { TF_Session* new_session = new TF_Session(session, graph); if (graph != nullptr) { mutex_lock l(graph->mu); graph->sessions[new_session] = ""; } return new_session; } else { DCHECK_EQ(nullptr, session); return nullptr; } } |
session.cc文件中的NewSession方法负责创建底层Session。
首先调用SessionFactory::GetFactory方法从前面注册的SessionFactory中获取一个适合的factory,在这里因为options中没有指定target,所以返回的是DirectSessionFactory。
然后通过factory->NewSession返回DirectSession。
Status NewSession(const SessionOptions& options, Session** out_session) { SessionFactory* factory; Status s = SessionFactory::GetFactory(options, &factory); if (!s.ok()) { *out_session = nullptr; LOG(ERROR) << s; return s; } // Starts exporting metrics through a platform-specific monitoring API (if // provided). For builds using "tensorflow/core/platform/default", this is // currently a no-op. session_created->GetCell()->Set(true); monitoring::StartExporter(); s = factory->NewSession(options, out_session); if (!s.ok()) { *out_session = nullptr; } return s; } |
以下为direct_session.cc中的NewSession方法,其中通过DeviceFactory::AddDevices方法添加计算设备:
Status NewSession(const SessionOptions& options, Session** out_session) override { const auto& experimental_config = options.config.experimental(); if (experimental_config.has_session_metadata()) { if (experimental_config.session_metadata().version() < 0) { return errors::InvalidArgument( "Session version shouldn't be negative: ", experimental_config.session_metadata().DebugString()); } const string key = GetMetadataKey(experimental_config.session_metadata()); mutex_lock l(sessions_lock_); if (!session_metadata_keys_.insert(key).second) { return errors::InvalidArgument( "A session with the same name and version has already been " "created: ", experimental_config.session_metadata().DebugString()); } } // Must do this before the CPU allocator is created. if (options.config.graph_options().build_cost_model() > 0) { EnableCPUAllocatorFullStats(true); } std::vector<std::unique_ptr<Device>> devices; TF_RETURN_IF_ERROR(DeviceFactory::AddDevices( options, "/job:localhost/replica:0/task:0", &devices)); DirectSession* session = new DirectSession(options, new DeviceMgr(std::move(devices)), this); { mutex_lock l(sessions_lock_); sessions_.push_back(session); } *out_session = session; return Status::OK(); } |
文件device_factory.cc中DeviceFactory::AddDevices方法,在这儿会找到上面启动是注册的ThreadPoolDeviceFactory:
Status DeviceFactory::AddDevices( const SessionOptions& options, const string& name_prefix, std::vector<std::unique_ptr<Device>>* devices) { // CPU first. A CPU device is required. auto cpu_factory = GetFactory("CPU"); if (!cpu_factory) { return errors::NotFound( "CPU Factory not registered. Did you link in threadpool_device?"); } size_t init_size = devices->size(); TF_RETURN_IF_ERROR(cpu_factory->CreateDevices(options, name_prefix, devices)); if (devices->size() == init_size) { return errors::NotFound("No CPU devices are available in this process"); } // Then the rest (including GPU). mutex_lock l(*get_device_factory_lock()); for (auto& p : device_factories()) { auto factory = p.second.factory.get(); if (factory != cpu_factory) { TF_RETURN_IF_ERROR(factory->CreateDevices(options, name_prefix, devices)); } } return Status::OK(); } |
然后在threadpool_device_factory.cc文件中调用CreateDevices方法完成ThreadPoolDevice的创建。名字就为/job:localhost/replica:0/task:0/device:CPU:0。
Status CreateDevices(const SessionOptions& options, const string& name_prefix, std::vector<std::unique_ptr<Device>>* devices) override { int num_numa_nodes = port::NUMANumNodes(); int n = 1; auto iter = options.config.device_count().find("CPU"); if (iter != options.config.device_count().end()) { n = iter->second; } for (int i = 0; i < n; i++) { string name = strings::StrCat(name_prefix, "/device:CPU:", i); std::unique_ptr<ThreadPoolDevice> tpd; if (options.config.experimental().use_numa_affinity()) { int numa_node = i % num_numa_nodes; if (numa_node != i) { LOG(INFO) << "Only " << num_numa_nodes << " NUMA nodes visible in system, " << " assigning device " << name << " to NUMA node " << numa_node; } DeviceLocality dev_locality; dev_locality.set_numa_node(numa_node); tpd = absl::make_unique<ThreadPoolDevice>( options, name, Bytes(256 << 20), dev_locality, ProcessState::singleton()->GetCPUAllocator(numa_node)); } else { tpd = absl::make_unique<ThreadPoolDevice>( options, name, Bytes(256 << 20), DeviceLocality(), ProcessState::singleton()->GetCPUAllocator(port::kNUMANoAffinity)); } devices->push_back(std::move(tpd)); } return Status::OK(); } |
ThreadPoolDevice的创建
上面的方法会调用threadpool_device.cc文件中ThreadPoolDevice构造方法完成ThreadPoolDevice的创建。构造函数调用父级构造函数LocalDevice。
ThreadPoolDevice::ThreadPoolDevice(const SessionOptions& options, const string& name, Bytes memory_limit, const DeviceLocality& locality, Allocator* allocator) : LocalDevice(options, Device::BuildDeviceAttributes( name, DEVICE_CPU, memory_limit, locality)), allocator_(allocator), scoped_allocator_mgr_(new ScopedAllocatorMgr(name)) |
文件local_device.cc中的构造函数如下,其中new LocalDevice::EigenThreadPoolInfo用于从SessionOptions中获取线程池信息,set_eigen_cpu_device(tp_info->eigen_device_.get())用于创建线程。
LocalDevice::LocalDevice(const SessionOptions& options, const DeviceAttributes& attributes) : Device(options.env, attributes), owned_tp_info_(nullptr) { // Log info messages if TensorFlow is not compiled with instructions that // could speed up performance and are available on the current CPU. port::InfoAboutUnusedCPUFeatures(); LocalDevice::EigenThreadPoolInfo* tp_info; if (OverrideGlobalThreadPoolFromEnvironment()) { set_use_global_threadpool(false); } if (use_global_threadpool_) { mutex_lock l(global_tp_mu_); if (options.config.experimental().use_numa_affinity()) { int numa_node = attributes.locality().numa_node(); int num_numa_nodes = port::NUMANumNodes(); DCHECK_LT(numa_node, num_numa_nodes); Allocator* numa_allocator = ProcessState::singleton()->GetCPUAllocator(numa_node); while (numa_node >= global_tp_info_.size()) { global_tp_info_.push_back(nullptr); } if (!global_tp_info_[numa_node]) { global_tp_info_[numa_node] = new LocalDevice::EigenThreadPoolInfo( options, numa_node, numa_allocator); } tp_info = global_tp_info_[numa_node]; } else { if (global_tp_info_.empty()) { global_tp_info_.push_back(new LocalDevice::EigenThreadPoolInfo( options, port::kNUMANoAffinity, nullptr)); } tp_info = global_tp_info_[0]; } } else { // Each LocalDevice owns a separate ThreadPoolDevice for numerical // computations. // TODO(tucker): NUMA for these too? owned_tp_info_.reset(new LocalDevice::EigenThreadPoolInfo( options, port::kNUMANoAffinity, nullptr)); tp_info = owned_tp_info_.get(); } set_tensorflow_cpu_worker_threads(&tp_info->eigen_worker_threads_); set_eigen_cpu_device(tp_info->eigen_device_.get()); } |
local_device.cc中的EigenThreadPoolInfo构造方法如下,首先从options中获取线程数量intra_op_parallelism_threads,如果没有从环境中获取,我们在环境变量中设置成了1,参见TensorFlow工程创建及设置中的环境变量设置。
explicit EigenThreadPoolInfo(const SessionOptions& options, int numa_node, Allocator* allocator) { // Use session setting if specified. int32 intra_op_parallelism_threads = options.config.intra_op_parallelism_threads(); // If no session setting, use environment setting. if (intra_op_parallelism_threads == 0) { static int env_num_threads = NumIntraOpThreadsFromEnvironment(); intra_op_parallelism_threads = env_num_threads; // If no session setting or environment, compute a reasonable default. if (intra_op_parallelism_threads == 0) { intra_op_parallelism_threads = port::MaxParallelism(numa_node); } } ThreadOptions thread_opts; thread_opts.numa_node = numa_node; eigen_worker_threads_.num_threads = intra_op_parallelism_threads; eigen_worker_threads_.workers = new thread::ThreadPool( options.env, thread_opts, strings::StrCat("numa_", numa_node, "_Eigen"), intra_op_parallelism_threads, !options.config.experimental().disable_thread_spinning(), /*allocator=*/nullptr); Eigen::ThreadPoolInterface* threadpool = eigen_worker_threads_.workers->AsEigenThreadPool(); if (allocator != nullptr) { eigen_allocator_.reset(new EigenAllocator(allocator)); } eigen_device_.reset(new Eigen::ThreadPoolDevice( threadpool, eigen_worker_threads_.num_threads, eigen_allocator_.get())); } |
上面的new thread::ThreadPool构造方法调用是在文件threadpool_device.cc文件中。
ThreadPool::ThreadPool(Env* env, const ThreadOptions& thread_options, const string& name, int num_threads, bool low_latency_hint, Eigen::Allocator* allocator) { CHECK_GE(num_threads, 1); eigen_threadpool_.reset(new Eigen::ThreadPoolTempl<EigenEnvironment>( num_threads, low_latency_hint, EigenEnvironment(env, thread_options, "tf_" + name))); underlying_threadpool_ = eigen_threadpool_.get(); threadpool_device_.reset(new Eigen::ThreadPoolDevice(underlying_threadpool_, num_threads, allocator)); } |
文件NonBlockingThreadPool.h中的构造方法Eigen::ThreadPoolTempl如下,其中会调用env_.CreateThread方法即在这儿为结构体方法EigenEnvironment.CreateThread。然后系统会会根据我们的设置创建一个线程,该线程主体就是调用WorkerLoop完成循环。
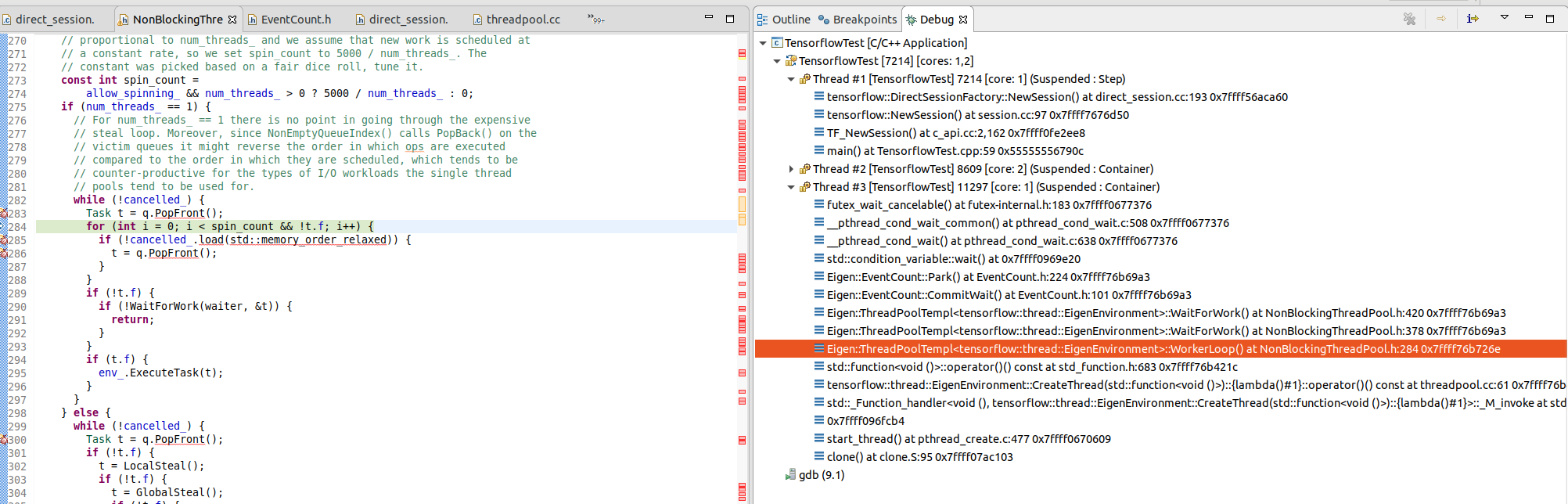
ThreadPoolTempl(int num_threads, bool allow_spinning, Environment env = Environment()) : env_(env), num_threads_(num_threads), allow_spinning_(allow_spinning), thread_data_(num_threads), all_coprimes_(num_threads), waiters_(num_threads), global_steal_partition_(EncodePartition(0, num_threads_)), blocked_(0), spinning_(0), done_(false), cancelled_(false), ec_(waiters_) { waiters_.resize(num_threads_); // Calculate coprimes of all numbers [1, num_threads]. // Coprimes are used for random walks over all threads in Steal // and NonEmptyQueueIndex. Iteration is based on the fact that if we take // a random starting thread index t and calculate num_threads - 1 subsequent // indices as (t + coprime) % num_threads, we will cover all threads without // repetitions (effectively getting a presudo-random permutation of thread // indices). eigen_plain_assert(num_threads_ < kMaxThreads); for (int i = 1; i <= num_threads_; ++i) { all_coprimes_.emplace_back(i); ComputeCoprimes(i, &all_coprimes_.back()); } #ifndef EIGEN_THREAD_LOCAL init_barrier_.reset(new Barrier(num_threads_)); #endif thread_data_.resize(num_threads_); for (int i = 0; i < num_threads_; i++) { SetStealPartition(i, EncodePartition(0, num_threads_)); thread_data_[i].thread.reset( env_.CreateThread([this, i]() { WorkerLoop(i); })); } #ifndef EIGEN_THREAD_LOCAL // Wait for workers to initialize per_thread_map_. Otherwise we might race // with them in Schedule or CurrentThreadId. init_barrier_->Wait(); #endif } } |
文件threadpool.cc中的结构体EigenEnvironment,它包括方法CreateThread,CreateTask和ExecuteTask。
struct EigenEnvironment { typedef Thread EnvThread; struct TaskImpl { std::function<void()> f; Context context; uint64 trace_id; }; struct Task { std::unique_ptr<TaskImpl> f; }; Env* const env_; const ThreadOptions thread_options_; const string name_; EigenEnvironment(Env* env, const ThreadOptions& thread_options, const string& name) : env_(env), thread_options_(thread_options), name_(name) {} EnvThread* CreateThread(std::function<void()> f) { return env_->StartThread(thread_options_, name_, [=]() { // Set the processor flag to flush denormals to zero. port::ScopedFlushDenormal flush; // Set the processor rounding mode to ROUND TO NEAREST. port::ScopedSetRound round(FE_TONEAREST); if (thread_options_.numa_node != port::kNUMANoAffinity) { port::NUMASetThreadNodeAffinity(thread_options_.numa_node); } f(); }); } Task CreateTask(std::function<void()> f) { uint64 id = 0; if (tracing::EventCollector::IsEnabled()) { id = tracing::GetUniqueArg(); tracing::RecordEvent(tracing::EventCategory::kScheduleClosure, id); } return Task{ std::unique_ptr<TaskImpl>(new TaskImpl{ std::move(f), Context(ContextKind::kThread), id, }), }; } void ExecuteTask(const Task& t) { WithContext wc(t.f->context); tracing::ScopedRegion region(tracing::EventCategory::kRunClosure, t.f->trace_id); t.f->f(); } }; |
上面的new Eigen::ThreadPoolDevice构造方法是在文件TensorDeviceThreadPool.h文件中。
struct ThreadPoolDevice { // The ownership of the thread pool remains with the caller. ThreadPoolDevice(ThreadPoolInterface* pool, int num_cores, Allocator* allocator = nullptr) : pool_(pool), num_threads_(num_cores), allocator_(allocator) { } |
上面调用的方法set_eigen_cpu_device在文件device_base.cc中:
void DeviceBase::set_eigen_cpu_device(Eigen::ThreadPoolDevice* d) { // Eigen::ThreadPoolDevice is a very cheap struct (two pointers and // an int). Therefore, we can afford a pre-allocated array of // Eigen::ThreadPoolDevice. Here, we ensure that // Eigen::ThreadPoolDevices in eigen_cpu_devices_ has increasingly // larger numThreads. for (int i = 1; i <= d->numThreads(); ++i) { eigen_cpu_devices_.push_back(new Eigen::ThreadPoolDevice( d->getPool(), i /* numThreads() */, d->allocator())); } } |
DirectSession的创建
经过上面代码对devices的创建,现在回到Session的创建上来。
方法thread_pools_.emplace_back(GlobalThreadPool(options), false /* owned */);用于创建运行op kernel的线程池。
在这儿由于inter_op_parallelism_threads也是1,所以调用完成后又会多一个线程运行op kernel的计算。
DirectSession::DirectSession(const SessionOptions& options, const DeviceMgr* device_mgr, DirectSessionFactory* const factory) : options_(options), device_mgr_(device_mgr), factory_(factory), cancellation_manager_(new CancellationManager()), operation_timeout_in_ms_(options_.config.operation_timeout_in_ms()) { const int thread_pool_size = options_.config.session_inter_op_thread_pool_size(); if (thread_pool_size > 0) { for (int i = 0; i < thread_pool_size; ++i) { thread::ThreadPool* pool = nullptr; bool owned = false; init_error_.Update(NewThreadPoolFromThreadPoolOptions( options_, options_.config.session_inter_op_thread_pool(i), i, &pool, &owned)); thread_pools_.emplace_back(pool, owned); } } else if (options_.config.use_per_session_threads()) { thread_pools_.emplace_back(NewThreadPoolFromSessionOptions(options_), true /* owned */); } else { thread_pools_.emplace_back(GlobalThreadPool(options), false /* owned */); // Run locally if environment value of TF_NUM_INTEROP_THREADS is negative // and config.inter_op_parallelism_threads is unspecified or negative. static const int env_num_threads = NumInterOpThreadsFromEnvironment(); if (options_.config.inter_op_parallelism_threads() < 0 || (options_.config.inter_op_parallelism_threads() == 0 && env_num_threads < 0)) { run_in_caller_thread_ = true; } } // The default value of sync_on_finish will be flipped soon and this // environment variable will be removed as well. const Status status = ReadBoolFromEnvVar("TF_SYNC_ON_FINISH", true, &sync_on_finish_); if (!status.ok()) { LOG(ERROR) << status.error_message(); } session_handle_ = strings::StrCat("direct", strings::FpToString(random::New64())); int devices_added = 0; if (options.config.log_device_placement()) { const string mapping_str = device_mgr_->DeviceMappingString(); if (mapping_str.empty()) { printf("Device mapping: no known devices.\n"); } else { printf("Device mapping:\n%s", mapping_str.c_str()); } string msg = strings::StrCat("Device mapping:\n", mapping_str); if (!logging::LogToListeners(msg)) { LOG(INFO) << msg; } } for (auto d : device_mgr_->ListDevices()) { devices_.push_back(d); device_set_.AddDevice(d); d->op_segment()->AddHold(session_handle_); // The first device added is special: it is the 'client device' (a // CPU device) from which we feed and fetch Tensors. if (devices_added == 0) { device_set_.set_client_device(d); } ++devices_added; } } |
本作品采用知识共享署名 4.0 国际许可协议进行许可。