原创文章,转载请注明: 转载自慢慢的回味
本文链接地址: Tensorflow Embedding原理
Embedding(嵌入)指的是把低维的流形嵌入到高维空间中。举个简单的例子,三维空间的球体(地球)是一个二维流形嵌入在三维空间(欧几里得空间),即地球上的任意一个点只需一个二维的经纬度就可以表达,但三维空间中用x,y,z。深度学习领域假设“自然的原始数据是低维的流形嵌入到原始数据所在的高维空间中”。所以,深度学习的过程就是把高维原始数据(图像,句子)再回映射到低维流形中,从而是数据变得可分,而这个映射就叫嵌入(Embedding)。比如文档Embedding,就是把每篇文档所组成的单词映射到一个低维的表征向量,使得每篇文档可以用一个表征向量来表示,即Embedding就是从原始数据提取出来的Feature,也就是通过神经网络映射之后的低维向量。
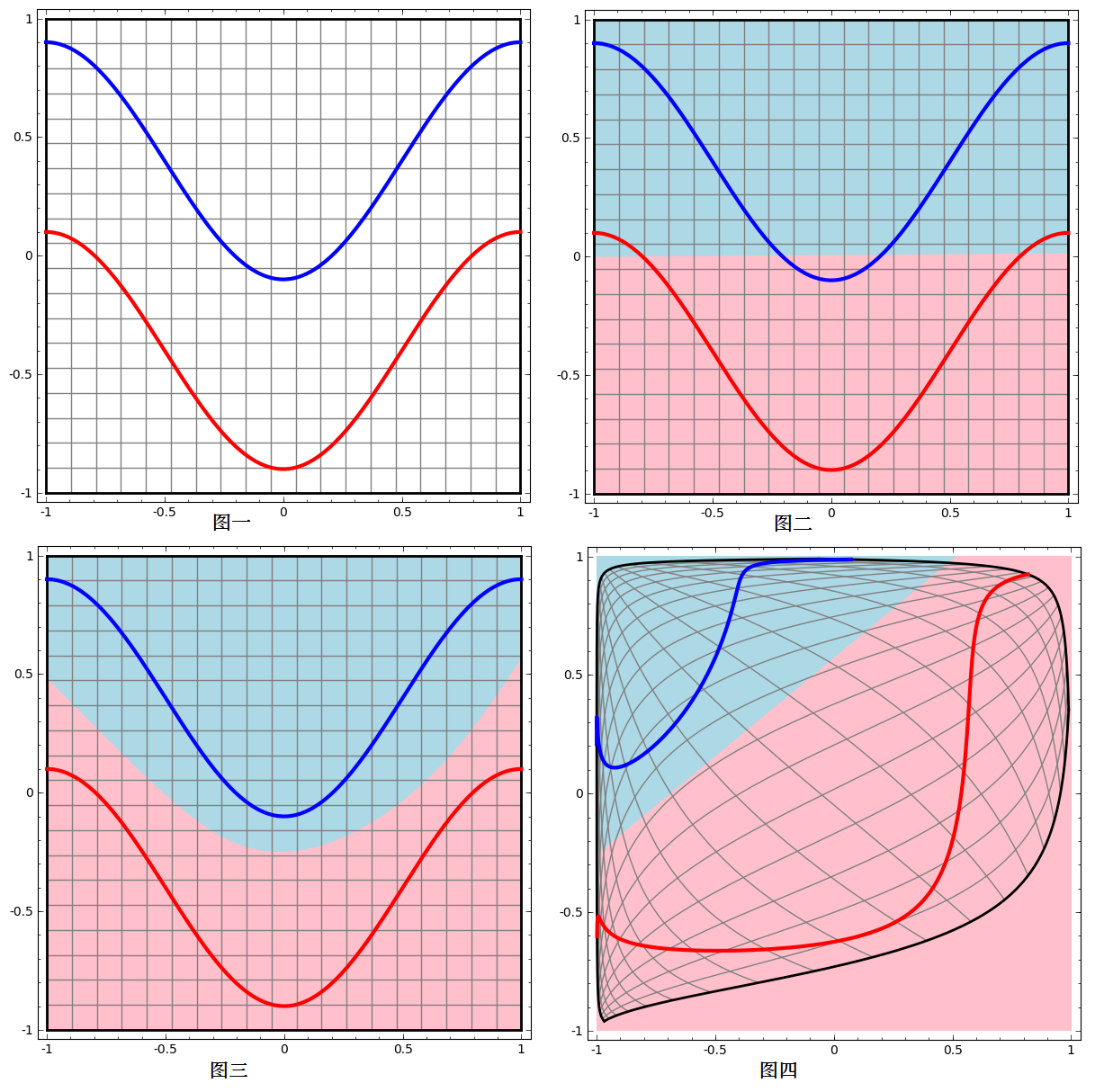
如下例子,蓝色曲线和红色曲线是无法线性可分的(图二),只能用非线性函数分离(图三),但真实的数据中却很难找到这样的非线性函数,但通过对数据进行Embedding过程进行映射后(图四),就可以线性可分了。
文档Embedding原理
在对文本进行分类的过程中,第一步便是需要对文本样本进行降维,比如文本字库大小为10000,不能用10000列队矩阵来进行全连接计算,由于每个样本大概只占300个单词的稀疏向量,所以我们可以用一个列数更少的致密向量来代替每个样本,即可以用300个Embedding向量来对所有的文档进行低维映射。
Embedding方法就是用来把文本样本的稀疏矩阵转换为致密矩阵的一个方法。
假设有如下的矩阵乘法:
一个由m个文本样本,每个样本由n个特征构成的稀疏向量,组成的样本库。每个样本中含有的单词用1表示,比如第一个样本有2个单词。
现在构建一个Embedding矩阵,大小为n * k。其中Embedding矩阵的值可以用uniform方法进行随机初始化。
用样本中对应1的位置进行Embedding向量选择,然后相加,得到最终的向量 [5 7 9 11]。这样,m * n 的稀疏矩阵就变成了 m * k 的致密矩阵了。