原创文章,转载请注明: 转载自慢慢的回味
本文链接地址: Tensorflow Conv2D和MaxPool2D原理
卷积神经网络(CNN)是指在所有网络中,至少优一层使用了卷积运算运算的神经网络,因此命名为卷积神经网络。
那么什么是卷积呢?如果需要卷积一个二位图片,首先定义一个卷积核(kernel),即权重矩阵,它能表面每一次卷积那个方向的值更重要,然后逐步在二维输入数据上“扫描卷积”。当卷积核“滑动”的同时进行卷积:计算权重矩阵和扫描所得的数据矩阵的乘积,求和后得到一个像素输出。
步长(Stride)为每次卷积核移动格数,填充(Padding)为是否对元素数据进行边缘填充。当不填充的时候,即Tensorflow中的VALID选项,卷积后的数据会比输入数据小,而加入合适的填充后,即Tensorflow中的SAME选项,卷积后的数据可以保持和输入数据大小一致。如下图所示:

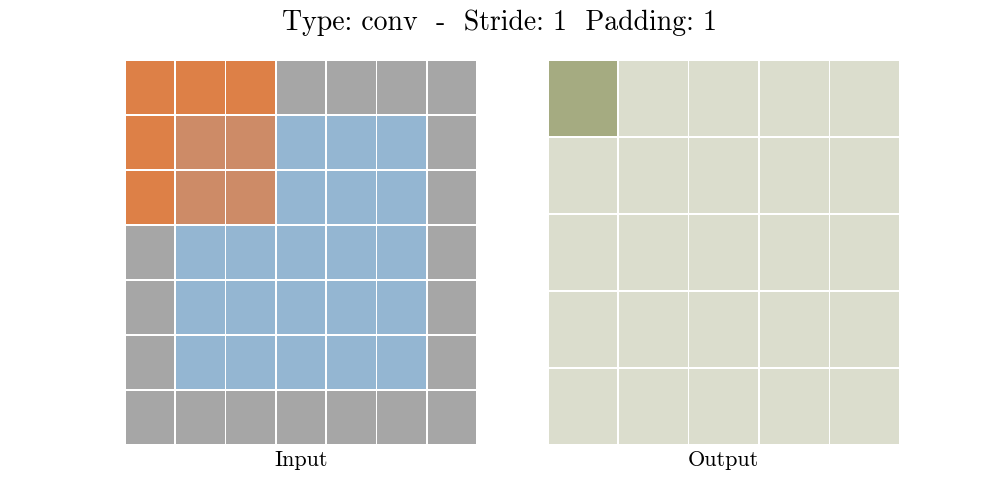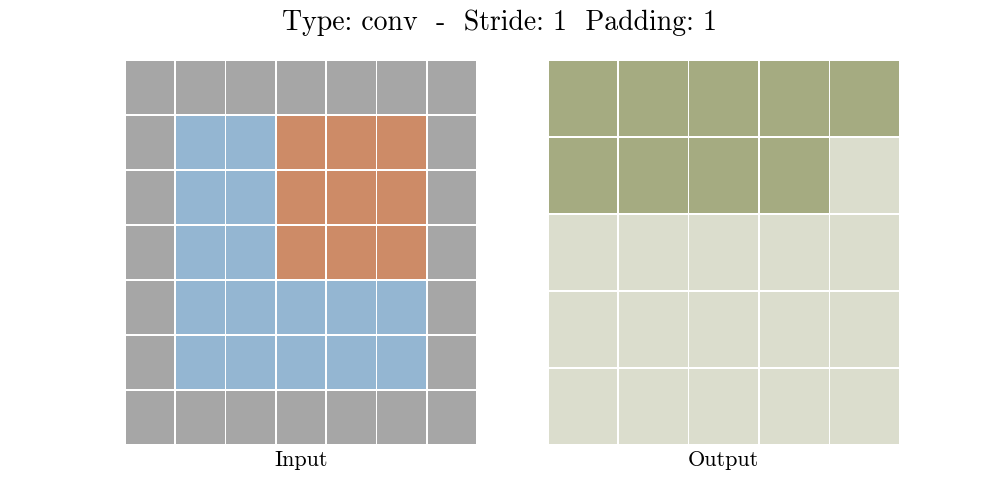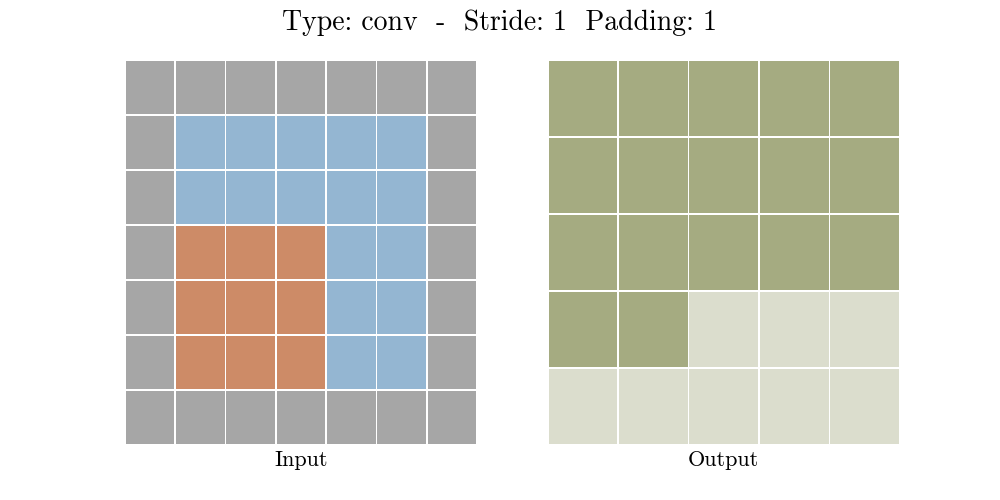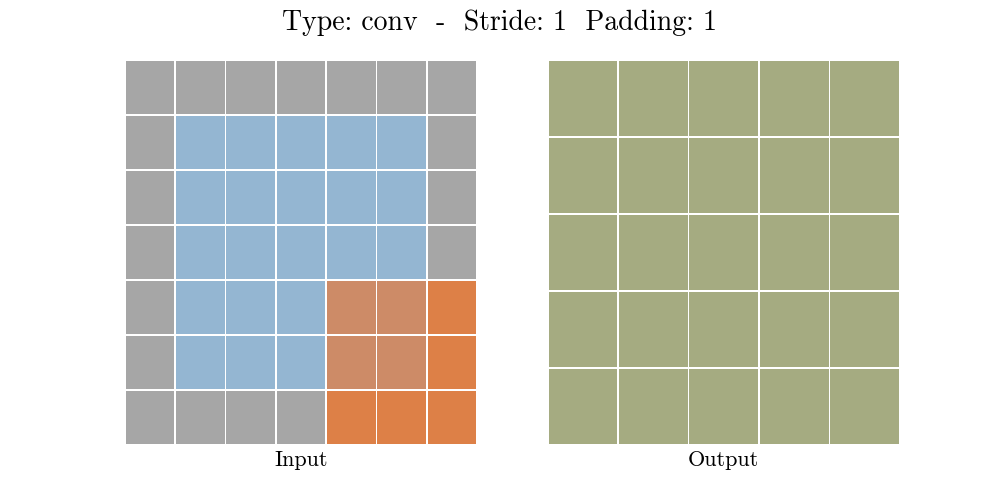


那么什么是池化呢?池化也称为欠采样或下采样。主要用于特征降维,在保持旋转、平移、伸缩等不变性的前提下,压缩数据和参数的数量,减小过拟合,同时提高模型的容错性。常用的有按均值池化(mean-pooling):更大地保留图像背景信息,按最大值池化(max-pooling):更多的保留纹理信息。如下图所示,池化大大压缩了数据:

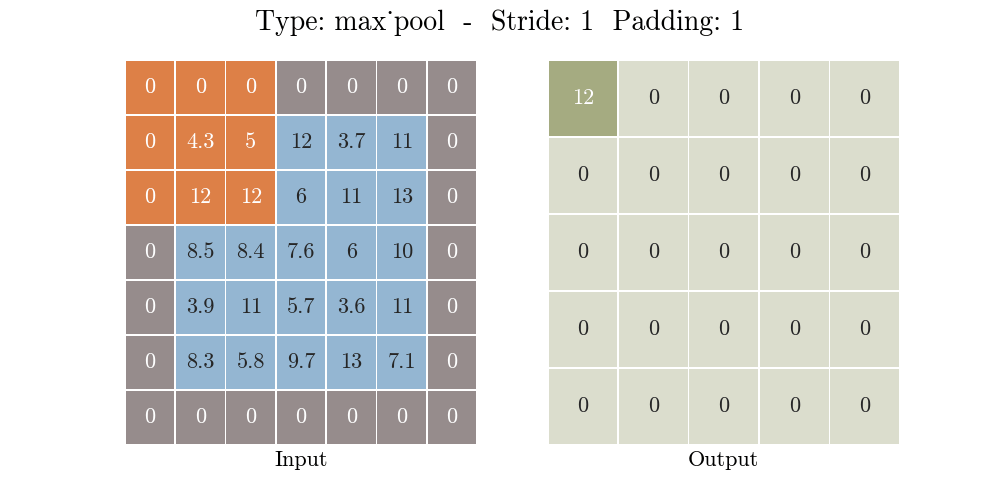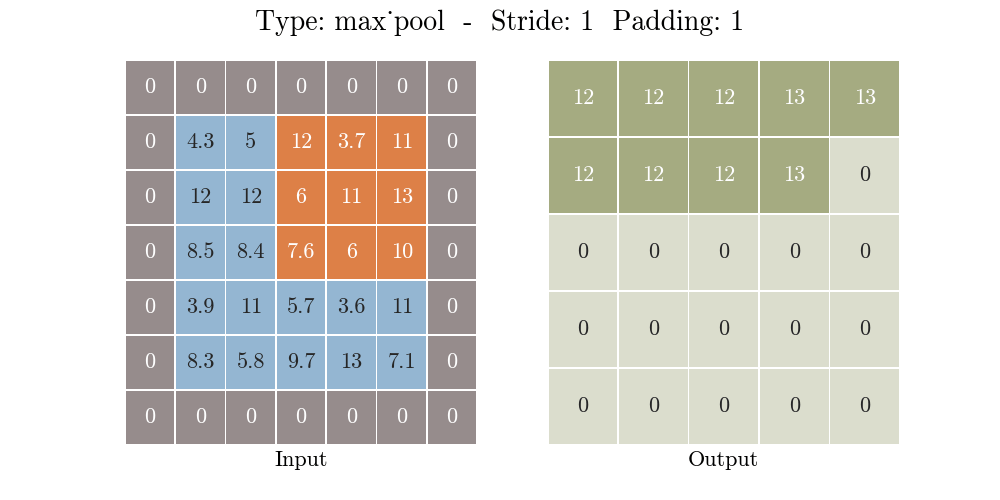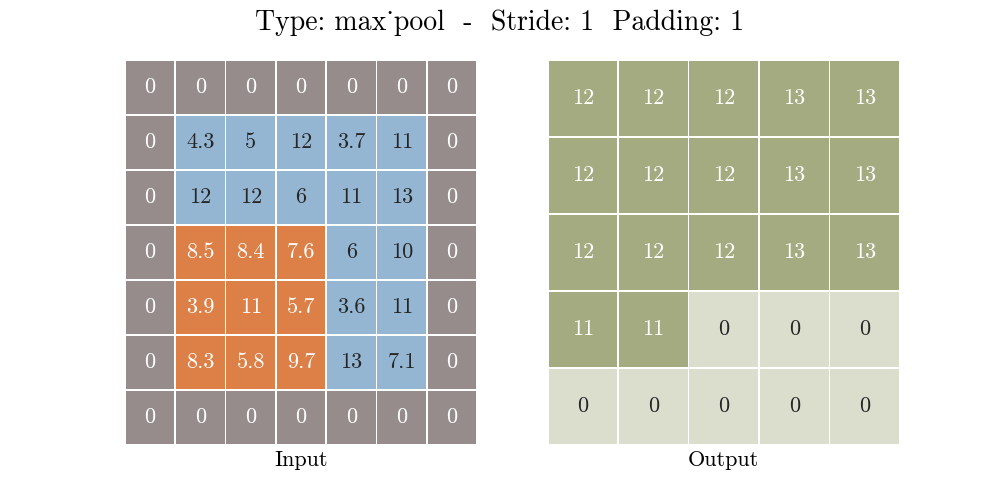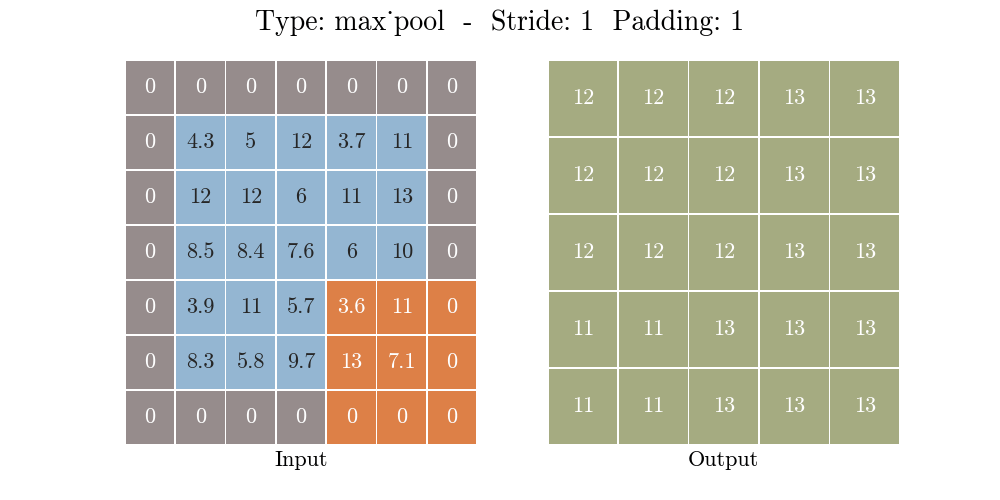
原理
以下面的测试程序来讨论Conv2D(卷积)和MaxPool2D(池化)的具体实现原理:
首先定义一个具有1张图,大小为6X6,通道为1个,即输入数据img的shape为[1,6,6,1]。
然后定义过滤器filter,NHWC格式,即批次,高,宽,通道格式,和输入数据是同一个格式。
下图为不同的卷积核对同一图片处理的结果:

测试程序
如下程序和图片示例,一个 3X3 的filter(卷积核的特征是提取图片从左上到右下的特征)在 6X6 的图片上,按照步长 1X1 从左往右,从上往下计算蒙版区域输出结果。
卷积计算:
图例1的卷积计算为:1*1 + 0*-1 + 0*-1 + 0*-1 + 1*1 + 0*-1 + 0*-1 + 0*-1 + 1*1 = 3
图例2的卷积计算为:1*1 + 0*-1 + 0*-1 + 0*-1 + 1*1 + 1*-1 + 0*-1 + 0*-1 + 0*1 = 1
继续阅读“Tensorflow Conv2D和MaxPool2D原理”本作品采用知识共享署名 4.0 国际许可协议进行许可。