原创文章,转载请注明: 转载自慢慢的回味
本文链接地址: GAN生成对抗网络的Keras实现
网络组成
GAN生成对抗网络包括2部分:
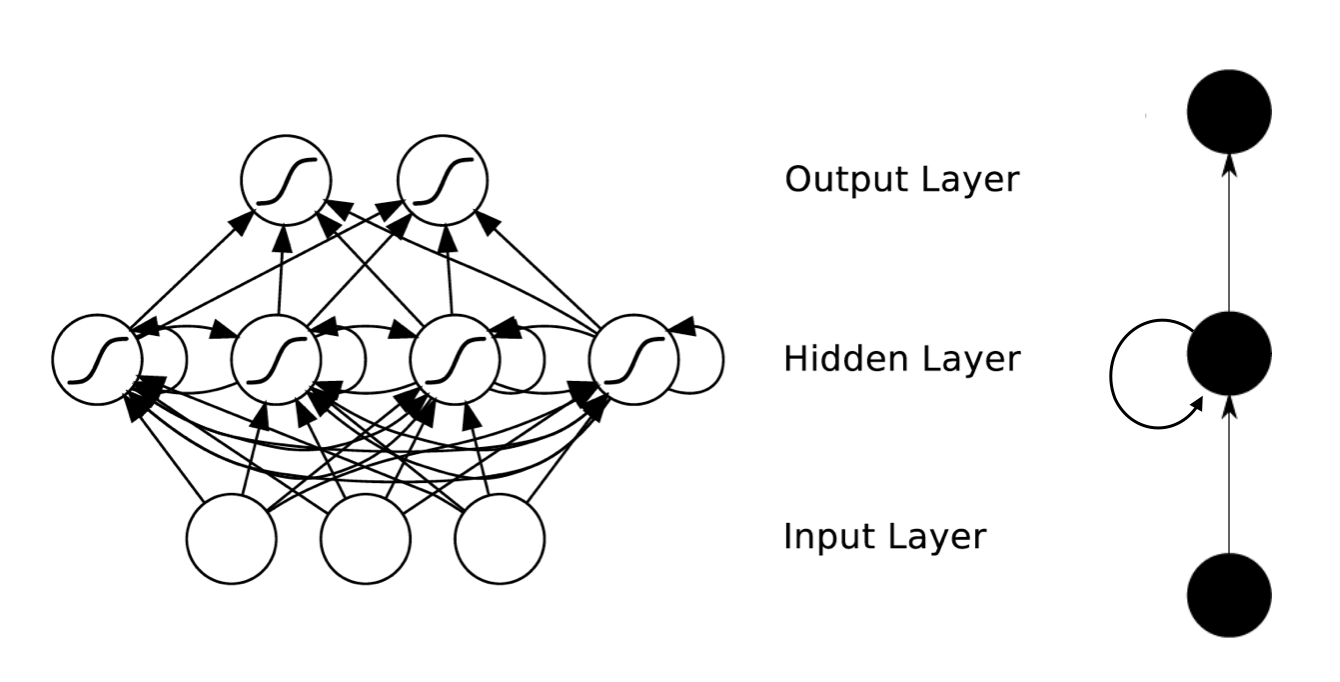
生成网络部分:它是一个多层神经网络结构,把一个高斯噪声通过网络生成一个图片数据,像是一个回归问题。
鉴别网络部分:它也是一个多层神经网络结构,把一个图片数据通过网络输出1或0,分辨出是不是真实图片,像是一个分类问题。
对抗的含义在于,生成网络总是想生成一个和真的一样的图片,鉴别网络部分总是想区分出谁是真实图片,谁是生成网络生成的。
理论推导网上很多,可以参考比如:GAN论文阅读——原始GAN(基本概念及理论推导)
程序分析
生成网络模型:
输入1X100的高斯分布向量 ->
256输出的全连接 -> 用ReLU进行分类 -> 正规化 ->
512输出的全连接 -> 用ReLU进行分类 -> 正规化 ->
1024输出的全连接 -> 用ReLU进行分类 -> 正规化 ->
图像大小(28X28X1)输出的全连接 -> 用tanh进行激活输出 -> 生成28X28X1的图片
返回的模型为:输入噪声,输出图片
继续阅读“GAN生成对抗网络的Keras实现”本作品采用知识共享署名 4.0 国际许可协议进行许可。